

LAB TEST : https://labex.io/learn
문항 1. Linux 운영체제에 대한 설명 중 맞는 것을 고르시오.
① 보안을 고려한 운영체제이므로 터미널 접속 시 기본적으로 telnet 를 사용하여 암호화 된 통신을 가능하게 한다.
② CentOS Stream 은 특정 버전의 Redhat Linux 가 정식 배포된 후, 해당 버전의 커널로 배포하는 커뮤니티 버전 OS이다.
③ RHEL7 이후부터 이전 버전의 Upstart(init) 가 systemd 로 변경되었고, systemd 가 PID 1번 프로세스가 된다.
④ free 명령어로 메모리 사용 현황을 조회할 수 있으며, 실제 메모리 사용량을 산정하기 위해서는 버퍼/캐시 사용량을 포함하여야 한다.
⑤ Azure 에서는 Azure 에 최적화 된 데비안 계열의 Azure Linux2 를 제공하고 있다.
<상세 해석>
① 기업에서 사용하는 대다수 Linux 운영체제(RHEL, OEL, Ubuntu 등)는 기본적으로 보안이 강화된 서비스와 규칙이 설정되어 있으며 sshd 서비스 활성화되어 22포트를 사용하여 /etc/sshd/sshd_config 설정파일을 통해 변경 가능(22포트는 이미 널려진 포트로 일반적으로 4자리 수 이상 포트 번호를 사용 권고)
② 2020년 7월 CentOS 정책변경으로 CentOS 프로젝트가 기존의 CentOS Linux 릴리즈 모델에서 CentOS Stream으로 전환하면서 Fedora RHEL CentOS에서 Fedora CentOS Stream RHEL Rocky Linux 제공
③ Kernel-3.10 부터 systemd 가 PID 1번 프로세스가 되며, Fedora, Ubuntu 등 OS 상위 커널 버전에서는 이미 지원
④ free 명령어로는 전체 물리메모리 확인, Buffer/Cache, Swap in/Out(Disk Cache) 사용량을 확인할 수 있으며 실제 메모리 사용량을 확인하려면 pmap <pid> 또는 cat /proc/smap 정보 종합적으로 확인 필요
⑤ MSFT 는 Azure Cloud 최적화된 별도 Linux OS 제공하지 않으며 사용자가 직접 Linux OS, Windows 등 선택하여 사용
문항 2. Linux 에서 FD(File Descriptor) 에 대한 설명 중 올바른 것을 고르시오.
① 프로세스가 실행 중에 파일오픈 혹은 소켓생성 시 FD 값은 1부터 순차적으로 부여된다.
② 프로세스가 OS에 요청할 수 있는 최대 오픈가능한 파일수를 초과할 경우 “Time out open files” 에러가 발생한다.
③ /proc/sys/fs/file-max 파일의 값을 변경하면 시스템 레벨에서 사용 가능한 FD 최대 개수, 즉 fs.file-max 값을 영구 변경할 수 있다.
④ /etc/security/limits.conf 파일 nproc 항목 설정을 통해 사용자 레벨의 FD 최대 개수를 제한할 수 있다.
⑤ Ulimit 명령어로 FD 의 soft limit 과 hard limit 을 설정할 수 있지만, 현재 쉘(shell) 세션에만 적용된다.
<상세 해석>
① 파일이 열릴 때마다 순차적으로 할당되며, 0, 1, 2는 표준 입력, 출력, 에러에 할당되어 있고, 이후에는 3부터 할당
② 프로세스가 가질 수 있는 최대 파일의 개수를 의미를 가지며 초과되는 경우 “Resource temporarily unavailable” 메시지를 발생
③ /proc/sys/fs/file-max :- 이것은 커널이 허용하는 동시에 열린 파일 descriptors 수입니다. 기본적으로 이 숫자는 시스템의 RAM 양에 따라 자동으로 달라집니다. System-wide 설정은 /etc/sysctl.conf fs.file-max = <N>, 사용자별 환경변수 설정은 /etc/security/limits.conf <username> soft nofile 4096 할 수 있습니다.
④ nproc는 사용자가 동시에 실행할 수 있는 프로세스 수를 제한하는 시스템 설정입니다.
⑤ ulimit –Sn, ulimit –Hn 명령어를 일시적으로 적용 가능, 영구적으로 설정하려면 /etc/security/limits.conf 설정
문항 3. Linux OS의 파일 및 권한에 대한 설명 중 옳은 것을 고르시오.
① 일반적인 OS설정(umask 022)에서 파일을 생성하면 권한이 755로 만들어지고 디렉토리를 생성하면 권한이 644로 만들어진다.
② root가 owner인 /bin/ksh 파일에 sticky bit 가 설정이 되어있다. 이 경우 /bin/ksh를 실행하는 일반유저가 root권한을 얻게 될 수 있으므로 즉시 sticky bit 를 제거해야 한다.
③ OS에서 파일의 inode번호는 시스템 전체에서 unique하기 때문에 root(/) 디렉토리부터 특정 inode번호로 전체 서버의 파일을 조회해보면 항상 1개만 검색이 된다.
④ root(/) 파일시스템 내에 /app 디렉토리의 owner가 user1이다. 신규로 파일시스템을 생성하여 /app 디렉토리에 마운트하면 /app의 owner가 root로 바뀌기 때문에 최초 1회는 권한 변경을 해주어야 한다.
⑤ /sw 디렉토리는 root유저 소유의 700권한이고 /sw/was01 디렉토리는 app01유저 소유의 755권한으로 되어 있다. 이 경우 app01유저가 /sw/was01디렉토리 내에 접근이 가능하다.
<상세 해석>
① 루트 사용자가 새 파일을 만들면 umask 가 022 (rwxr-xr-x)로 설정되고 파일의 기본 권한이 666 (rw-rw-rw-)으로 설정됩니다. 이렇게 하면 기본 권한이 644 (-rw-r-r--). 루트 사용자가 새 디렉토리를 만들면 umask 가 022 (rwxr-xr-x)로 설정되고 디렉터리의 기본 권한이 777 (rwxrwxrwx)으로 설정됩니다. 이렇게 하면 기본 권한은 755 (rwxr-xr-x)
② Sticky bit는 파일이나 디렉토리에 설정할 수 있는 특수 권한 비트입니다. 디렉토리에 설정될 때 의미가 있습니다:
/tmp 같은 디렉토리에 sticky bit를 설정하면, 해당 디렉토리 내 파일을 소유자만 삭제/이름 변경할 수 있습니다.
Sticky bit는 디렉토리에 설정 시에만 의미가 있음. /bin/ksh에 sticky bit가 설정되어 있어도, root 권한 상승과는 무관.
③ inode 번호는 파일 시스템 내에서만 유일합니다. 즉, 같은 파일 시스템(마운트 포인트) 내에서는 inode 번호가 중복되지 않습니다. 같은 파일 시스템 내에서 여러 파일 이름이 동일한 inode 번호를 가리킬 수 있습니다. 즉, 같은 inode 번호를 갖는 파일이 여러 개 존재할 수 있습니다.
④ 마운트 후 /app은 새로운 파일시스템의 루트 디렉토리를 나타내며, 기본적으로 root 소유. 최초 1회 권한 변경 (소유자 변경) 필요.
⑤ 디렉토리에 접근(진입)하려면 그 디렉토리 뿐 아니라 상위 모든 디렉토리에 대해 x (execute) 권한이 있어야 합니다.
문항 4. 다음은 어떤 회사의 네트워크 구성도이다. 다음 조건을 감안하여 보기 중 잘못된 것을 고르시오.
[조건] - WEB 대역의 서버들은 스위치 장비를 통해 Load Balancing 구성되어 있다.
- 사무실 대역은 서버팜 대역과 다른 네트워크 대역을 사용한다.
- 구성도의 1번, 2번, 3번 스위치 장비는 아이콘 그림이 같으면 같은 기능의 스위치 장비, 다르면 다른 기능의 스위치 장비이다. (허브(Hub) 장비는 사용하고 있지 않다.)
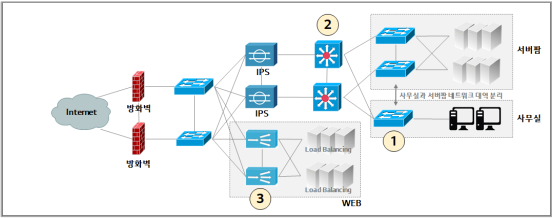
① 1번 스위치는 서버의 MAC을 인식할 수 있다.
② 1번 스위치는 기능이 단순하여 실제적인 이중화 구성이 불가능하다.
③ 2번 스위치는 라우팅(Routing) 기능이 있다.
④ 2번 스위치 장비는 패킷의 IP를 인식할 수 있다.
⑤ 3번 스위치 장비는 패킷의 TCP 프로토콜을 인식할 수 있다.
<상세 해석>
① L2 스위치는 MAC 주소를 인식하고 이를 기반으로 데이터를 전달합니다. L2 스위치는 데이터 링크 계층 장비로, MAC 주소를 학습하여 해당 주소가 연결된 포트로 프레임을 전달하는 역할을 합니다.
② 이중화는 시스템이나 장비의 신뢰성을 높이기 위한 중요한 전략입니다. L2 스위치 이중화는 주로 Spanning Tree Protocol (STP)을 사용하여 루프를 방지하고, 필요한 경우 백업 링크를 통해 네트워크 가용성을 높입니다.
③ L3 스위치는 OSI 모델의 네트워크 계층(3계층)에서 동작하며, 라우팅 기능을 수행하여 서로 다른 네트워크 또는 VLAN 간의 데이터 패킷 전달을 담당합니다. 즉, L3 스위치는 IP 주소를 기반으로 라우팅 결정을 내리고, 패킷을 올바른 네트워크로 전달하는 역할을 합니다.
④ L3 스위치는 패킷의 IP 주소를 인식하고 이를 기반으로 라우팅 결정을 합니다. L3 스위치는 데이터 링크 계층 (L2) 스위칭 기능과 네트워크 계층 (L3) 라우팅 기능을 모두 제공합니다. 따라서 L3 스위치는 패킷의 IP 헤더를 읽어 목적지 IP 주소를 확인하고, 라우팅 테이블을 참조하여 패킷을 적절한 다음 홉으로 전달합니다.
⑤ IPS는 네트워크 트래픽을 실시간으로 감시하고 분석하여 비정상적인 활동이나 공격 패턴을 탐지하고 차단합니다. 이때 TCP 프로토콜을 포함한 다양한 프로토콜을 분석하여 공격 유형을 식별하고 대응합니다.
문항 5. 다음은 어떤 리눅스 서버에서 보안 취약성 점검 결과로 도출된 취약점을 확인한 것이다. 공격자가 어떤 방법으로 이 취약성을 이용할 수 있는지 가장 적절히 설명된 것을 고르시오.
[P]apserver01::root::/root # crontab -l -u root 0 0 * * * /ISC/sorc001/Checker.sh >/dev/null 2>&1
0 7 * * * /ISC/sorc001/SCRIPTS/get_sysinfo_Linux.sh 2>&1 > /dev/null 0 0 * * * /usr/bin/nmon -ft -s 300 -c 288 -m /ISC/AdminHelper/LOGS/nmon [P]apserver01::root::/root # ls -l /ISC/sorc001/SCRIPTS/get_sysinfo_Linux.sh -rwxrwxrwx 1 root root 5929 Feb 27 17:07 /ISC/sorc001/SCRIPTS/get_sysinfo_Linux.sh
① Root 소유의 crontab 이기 때문에 일반 사용자는 확인이 불가능 하다.
② Cron schedule을 사용자가 수정할 수 있어 시스템 정보를 취득할 수 있다.
③ Checker.sh란 파일을 조작하여 임의의 파일을 실행할 수 있다.
④ Root 로 수행되는 파일을 수정하여 임의의 명령을 root 권한으로 실행할 수 있다.
⑤ Root 소유의 스크립트이기 때문에 임의의 사용자는 수정이 불가능 하다.
<상세 해석>
① crontab –e <사용자> 명령어로 추가된 설정은 crontab –l 또는 –u 옵션 활용하여 환경설정을 확인할 수 있습니다.
② crontab –l –u root 명령어로 설정된 환경설정은 해당 사용자(root)만이 설정할 수 있습니다.
③ 보기에서는 스크립트 실행 권한을 알 수 없지만 crontab –l –u root 명령어로 확인되어 일반사용자는 수정 불가 유추
④ root 사용자가 만들었다고 하더라도 rwxrwxrwx(0777) 권한부여 시 일반사용자가 생성/편집/실행 가능
⑤ 3번 문항 내용과 동일
문항 6. Linux 에서 사용자 권한 관리에 사용되는 sudo 명령에 관한 설명 중 잘못된 것을 고르시오.
① su 명령어에 비해 sudo 명령어를 사용하여 root 권한으로 명령어를 실행하는 것이 보안상 더 안전하다.
② sudo 권한 설정 파일인 /etc/sudoers 파일의 기본 퍼미션은 440 이다.
③ /etc/sudoers 파일내 NOPASSWD 구문을 제거한 후 sudo 명령을 실행하면 root 패스워드 입력이 요구된다.
④ visudo 명령어를 사용하여 /etc/sudoers 파일 편집하면 저장 시 파일 구문의 유효성을 검사한다.
⑤ /etc/sudoers 파일내에 사용자뿐만 아니라 그룹에 대한 sudo 설정도 가능하며, 그룹명 앞에는 % 식별자를 붙여준다.
<상세 해석>
① su 와 sudo 는 모두 상승된 권한을 얻는 데 사용되는 명령이지만 이를 달성하는 방법과 사용법이 다릅니다. sudo를 사용하면 루트 권한으로 단일 명령을 실행할 수 있는 반면, su를 사용하면 루트를 포함한 다른 사용자 계정으로 전환하고 세션이 종료될 때까지 해당 사용자의 환경에 대한 전체 액세스 권한을 얻을 수 있습니다.
② Linux에서 /etc/sudoers 파일은 매우 민감한 보안 설정 파일입니다. sudo 는 보안을 강화하기 위한 절차이지만 최근에 보안 이슈는 sudo 취약점에 의해 오히려 악영향을 미칠 수 있는 조건으로 지속적으로 보고되고 있어 doas, pkexec 또는 run0 대체 방안이 거론됩니다. 기본 권한(퍼미션) –r--r----- root root 과 같이 0440 입니다.
③ %sudo ALL=(ALL) NOPASSWD: ALL 이 설정이 있으면, sudo 권한이 있는 사용자가 sudo 명령어를 입력할 때 비밀번호를 묻지 않습니다.
NOPASSWD 구문 제거 후 sudo 권한이 있는 사용자가 sudo 명령어를 실행할 때 비밀번호를 입력해야만 실행됩니다. (NOPASSWD 존재: 비밀번호 없이 sudo 사용 가능, NOPASSWD 제거: sudo 사용 시 비밀번호 필요.)
④ 편집중에 실수로 권한이 잘못되면 보안 취약점이 생기거나 sudo가 정상 작동하지 않을 수 있기 때문에 쓰기 권한은 부여하지 않고 visudo 명령어를 사용해 안정하게 수정하도록 권장하지만 파일 구문의 유효성은 검사하지는 않습니다.
⑤ 예를 들어 %wheel ALL=(ALL) ALL 설정하는 경우, wheel 그룹에 속한 모든 사용자들이 sudo(관리자 권한) 명령을 사용할 수 있도록 허용하게 됩니다.
문항 7. 다음은 서버 이중화를 구성하기 위해 작성한 구성도이다. 이 구성도의 네트워크 설정에 대하여 설명한 것으로 옳은 것을 고르시오.
① Teaming Ⓐ 와 Teaming Ⓑ 를 설정 시 각각 Default Gateway를 등록하여야 한다.
② Teaming Ⓐ 구성 시 NIC 2개에 각각 다른 IP 할당이 필요하며, 그 중 하나의 IP를 사용하게 된다.
③ 별도 인터페이스가 없다면, Server#1 에서 총 6개의 활성화된 네트워크 어댑터가 조회된다.
④ Teaming 방식을 라운드 로빈으로 설정하는 것 만으로도 대역폭을 2G로 확대하는 효과를 얻을 수 있다.
⑤ 이중화를 위한 Cluster Service IP는 양 서버의 Teaming NIC에 동시에 Alias 되어 있어야 한다.
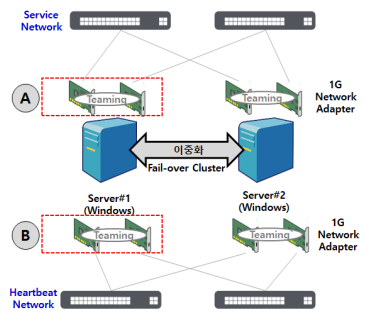
<상세 해석>
① Heartbeat Network는 High Availability(고가용성)구성에 필요로 하는 네트워크로 Default Gateway가 없어도 무방합니다.
② team0 구성에 eth0 와 eth1 2개 이상 NIC 필요하며 각각의 IP Address 는필요하지 않습니다.
③ team0 - eth0과 1 그리고 team1 - eth2과 3 구성으로 team0 와 team1 가상 네트워크 활성화 되며 이와 함께 물리/논리 NIC – eth0, 1, 2, 3 모두 총 6개활성화가 되게 됩니다.
④ round-robin은 Active-Active 구조(mode 1 의 Packet을 분산하는 역할)이고, mode 4(802.3ad) 필요하지만 Switch에서 link aggregation 설정이 추가로 필요합니다.
⑤ 서버 이중화 구성 시 team0 – mode 1를 사용하며 이 때 team0에 속한
NIC(eth0, eth1) 둘 중에 하나의 NIC에서 alias 되어 보여집니다.
문항 8. A사 가상화 시스템을 제안 중이다. 업무 시스템을 용도에 따라 분류하고 전체 시스템 자원 규모를 계산하니 CPU 514core, 메모리 3,972GB가 필요한 것으로 산출되었다. 도입 예정인 A사 표준 x86 물리서버 1대의 spec.이 CPU 32core, 메모리 1,024GB 일 때, 필요한 업무용 물리서버 대수를 산정하시오. 단, 가상화율은
CPU 300%, 메모리 100%로 하고, Hypervisor 오버헤드 5%, 물리서버의 운영 임계치는 CPU와 메모리 모두 85%로 한다.
※ 전제사항 : 문항에 제시된 요건 이외의 항목은 고려하지 않는다. (ex. 가용성 확보 위한 이중화, Standby 서버, HyperThread 적용 등)
① 물리서버 4대
② 물리서버 5대
③ 물리서버 6대
④ 물리서버 7대
⑤ 물리서버 8대
<상세 해석>
전체 필요한 자원 - CPU : 514 core, 메모리 3,972GB, 물리서버 1대 스펙 - CPU 32 core, 메모리 1,024GB
조건 : 가상화율 CPU 300%, 메모리 100%, 하이퍼바이저 오버헤드 5%, 운영임계치 85%
1. CPU기준 계산 :
- CPU 가상화율 적용 : 300% 32 core × 3 = 96 vCPu
- 하이퍼바이저 오버헤드 적용 : 96 vCPU × (1-0.05) = 91.2 vCPU
- 운영 임계치 적용 : 91.2 vCPU * 0.85 = 77.52 vCPU
필요서버 대수(CPU기준) ==> 514 / 77.52 = 6.63 (반올림 7대)
2. 메모리 기준 계산 :
- 메모리 가상화율 적용 : 메모리 가상화율 100% → 1,024 GB
- 하이퍼바이저 오버헤드 적용 : 1,024 GB × (1-0.05) = 972.8 GB
- 운영 임계치 적용 : 972.8 GB × 0.85 = 827.88 GB
필요서버 대수(메모리 기준) ==> 3,972 ÷ 827.88 ≈ 4.80 → 올림해서 5
문항 9. K사는 K8s(Kubernetes)를 이용하여 어플리케이션 서비스를 배포/관리하고 있다. K8s Cluster에서는 stateful 데이터 저장을 위해 PV(Persistent Volume)를생성하고 Pod에서 사용하도록 한다. 다음 중 Node 단위로 데이터가 유지되는 PV의 유형을 고르시오.
① emptyDir
② hostpath
③ Network Volume
④ Cluster Volume
⑤ vsphereVolume

<상세 해석>
① emptyDir 은 파드가 생성될 때 생성되고 파드와 함께 삭제되는 임시 저장소, 컨테이너들끼리 데이터를 공유하기 위해서 볼륨
② hostpath 는 파드가 동작하는 쿠버네티스 클러스터의 노드(host)의 로컬 파일시스템의 파일 및 디렉토리를 파드가 사용할 수 있는 볼륨
③ 쿠버네티스에서 네트워크 볼륨(Network Volume)은 네트워크를 통해 접근 가능한 스토리 지를 의미, NFS, iSCSI, Ceph 등
④ 쿠버네티스 클러스터에서 볼륨(Volume)은 파드(Pod) 내의 컨테이너가 데이터를 저장하고 공유할 수 있도록 하는 추상화된 개념
⑤ vsphere Volume 은 vSphere VMDK 볼륨을 파드에 마운트하는데 사용된다. 볼륨을 마운트 해제해도 볼륨의 내용이 유지
문항 10. 고객사는 그림과 같이 다양한 방식의 스토리지 시스템을 활용하고 있다. 각 스토리지 시스템 구성에 대한 설명 중 틀린 것을 고르시오.
① A 서버는 TCP 네트워크 기반의 iSCSI 프로토콜을 사용하여 iSCSI 스토리지에서 제공하는 볼륨을 인식할 수 있으며, 이 경우 안정적인 LAN 네트워크가 요구된다.
B 서버는 A 서버와 iSCSI 스토리지의 동일 볼륨/파일을 공유하기 위해 별도의 볼륨/파일 공유 솔루션이 필요하지 않다.
② A 서버는 NAS 스토리지에서 제공하는 특정 디렉토리를 TCP 네트웍을 통해 사용할 수 있으며, 이 경우 스토리지 네트워크로 LAN 네트워크가 요구된다. B 서버는 A 서버와 NAS 스토리지의 디렉토리나 파일을 서로 공유할 수 있다.
③ A 서버는 SAN 스토리지에서 제공하는 특정 디스크 볼륨을 디스크로 인식하고 마치 로컬 디스크처럼 포맷하여 사용할 수 있으며, 이 경우 FC 기반의 별도 스토리지 네트웍이 요구된다. B 서버는 A 서버와 SAN 스토리지의 동일 볼륨/파일을 서로 공유하기 위해서는 별도의 볼륨/파일 공유 솔루션이 필요하다.
④ A 서버는 DAS 스토리지와 바로 연결되어 있으며 DAS 스토리지에서 제공하는 볼륨을 인식할 수 있다. B 서버는 직접적으로 DAS 스토리지에서 제공하는 볼륨을 인식할 수 없다.
⑤ iSCSI와 NFS는 네트워크 대역폭 및 스위치 자원 사용율을 같이 모니터링하고 서버에서 TCP/IP관련 파라미터를 튜닝하는 것이 바람직하다.

<상세 해석>
① iSCSI는 블록 단위 스토리지로, 기본적으로 한 서버가 단독으로 마운트하여 사용하도록 설계되어 있습니다.
여러 서버가 동시에 동일한 LUN에 접속해서 파일 시스템을 공유하려면 충돌과 데이터 손상 위험이 있습니다. 클러스터 파일 시스템(예: GFS2, OCFS2) 같은 볼륨/파일 공유 솔루션이 반드시 필요합니다.
② NAS는 파일 시스템을 네트워크 상에 공유된 형태로 제공하기 때문에, 여러 서버(A, B)가 동시에 같은 공유 디렉토리(NFS export 혹은 SMB share)를 마운트해서 같이 접근하고 파일을 공유할 수 있다.
③ SAN 볼륨(LUN)은 기본적으로 단일 서버 전용으로 설계됩니다. 여러 서버가 동일 볼륨을 공유하려면 클러스터 파일 시스템(예: GFS2, OCFS2, Veritas CFS 등) 같은 별도의 공유 파일 시스템 솔루션이 필요합니다. 그렇지 않으면 데이터 충돌 및 파일 시스템 손상이 발생합니다.
④ DAS는 네트워크 공유 기능을 기본적으로 제공하지 않기 때문에, 다른 서버(B 서버)는 직접적으로 DAS 볼륨에 접근할 수 없습니다. 만약 B 서버에서 접근하려면, A 서버가 파일 공유 (NFS, SMB 등) 를 설정해 주어야 하며, 이 경우에도 A 서버를 거쳐야만 합니다.
⑤ iSCSI는 TCP/IP 기반 블록 스토리지 프로토콜입니다. 네트워크 대역폭을 많이 사용하며, 특히 대규모 I/O를 처리할 때 스위치, NIC, 서버의 TCP 스택 자원이 중요합니다. NFS도 TCP/IP 기반 파일 공유 프로토콜입니다. 네트워크를 통해 파일을 공유하기 때문에 마찬가지로 네트워크 대역폭과 스위치 리소스를 많이 사용합니다. 프로토콜 모두 네트워크 의존도가 높기 때문에, 네트워크 대역폭, 스위치 포트 사용률, 패킷 지연, 재전송율 등 모니터 링이 매우 중요
문항 11. 다음은 노후 스토리지 교체를 위해 신규 스토리지 도입 후 Data 이관 과정을 설명한 내용들이다. 스토리지 이관 방안 중 잘못된 것을 고르시오.
① Disk-To-Disk 복제 솔루션으로 사전 디스크 복제를 수행 후, 신규 스토리지로 연결하여 이관을 완료하였다.
② LVM으로 신규 스토리지로 LV Mirror 구성 후, 기존 스토리지를 분리하여 Online 이관 작업을 진행하였다.
③ 대용량 DB Data를 rsync로 신규 스토리지와 동기화하여 최소한의 Offline 시간으로 이관을 완료하였다.
④ 개발 AP서버의 서비스를 종료 후, Filesystem을 Readonly로 Re-Mount한 후 rsync로 데이터 복제하여 이관 완료하였다.
⑤ 노후 스토리지에서 OS상의 VG를 10개나 만들어서 사용하여 관리가 불편하였기에 신규 스토리지를 Tape 백업 및 복구 방식으로 이관할 때 OS상에서 VG를 3개로 통합하여 구성하였다.
<상세 해석>
① Disk-To-Disk 복제 솔루션은 기존 디스크 데이터를 새로운 디스크(스토리지)로 복제하는 솔루션을 의미합니다. (예: Zerto, Veritas Volume Replicator, EMC SRDF 등.) 실제로 스토리지 마이그레이션, 데이터센터 이전, 또는 DR 구축 시 흔히 사용되는 방식. 특히 중단 시간을 최소화하기 위해 사전 복제를 하고, 최종 전환 시점에 연결을 바꿔 이관을 완료하는 전략
② LVM 미러는 기존 스토리지와 신규 스토리지 간 데이터를 실시간으로 동기화합니다. 이 단계에서 서비스는 중단되지 않고(Online) 진행되며 서비스 중단 없이, 신규 스토리지로 데이터 이관 완료
③ DB가 Online 상태에서 rsync로 복제하면, 파일 일관성이 깨질 수 있음 (특히 InnoDB, Oracle, PostgreSQL 등 대부분 DBMS). 보통 DB를 “shutdown” 또는 “backup 모드”로 전환하고 복제를 진행해야 데이터 무결성을 보장. DB에 따라서는 rsync 대신 스토리지 스냅샷, 복제 도구 (예:
mysqldump, pg_basebackup, RMAN 등) 를 사용하는 것이 더 권장 대용량 DB 데이터를 rsync로 사전 복제(동기화)한 후, 서비스 중단(Offline) 시간을 최소화하여 최종 증분 복제를 수행하고 신규 스토리지로 전환하여 이관을 완료. 가 방법을 수정하여 진행은 가능
④ 먼저 서비스(웹 애플리케이션, API 등)를 중단하여 더 이상 파일이 변경되지 않도록 하고 이후에는 파일시스템을 read-only 모드로 다시 마운트 (예제. mount -o remount,ro /mountpoint) 이 단계에서 데이터 변경이 불가능하게 되어 데이터 일관성 보장해야 함. rsync로 신규 스토리지 또는 신규 서버에 복제 진행 방식은 실제 운영 환경에서 DB나 중요 파일 복제 시 많이 쓰는 패턴
⑤ 백업 & 복구 방식은 VG 및 LV 구성을 새롭게 재설계할 기회가 됨. 실제로 스토리지 마이그레이션 시 VG 구조를 최적화하는 사례 많음. OS 관점에서 VG 통합은 복구 시점에 새롭게 생성 가능.
문항 12. 다음 사례를 읽고 고객의 요구사항에 가장 충실한 백업 구성 방안을 고르시오. 컨텐츠 관리 시스템의 백업 환경을 개선하고자 한다. 최근 장애들을 면밀히 분석해본 결과, 운영자 혹은 사용자의 실수로 인한 파일 삭제가 대부분을 차지하고 있었다. 고객은 파일 삭제 발생 시 최대한 손실없이 복구가 가능하도록 백업 시스템 개선을 요구하였다.
① PTL(Physical Tape Library)을 이용하여 매일 1회 Hot 백업(Full 백업)을 수행하고 30분 간격으로 Incremental 백업을 수행한다.
② 스토리지 복제 솔루션을 이용하여 매일 4회(6시간 간격) 스토리지 복제를 수행한다.
③ 스토리지 복제 솔루션을 이용하여 매일 2회(0시, 12시) 스토리지 복제를 수행하고, 복제본을 PTL(Physical Tape Library)을 이용하여 Tape으로 다시 백업 받는다.
④ 스토리지 복제 솔루션을 이용하여 매일 2회(0시, 12시) 스토리지 복제를 수행하고, 00시 복제본을 PTL(Physical Tape Library)을 이용하여
Tape으로 백업 받은 뒤, 해당 백업본은 원격지 소산을 수행한다.
⑤ tar커맨드를 사용하여 매 2시간 간격으로 별도의 디렉토리에 복사하고 기존 tar파일은 삭제한다.
<상세 해석>
① Full + Incremental 조합은 흔히 사용되는 표준 전략. Incremental 주기를 짧게 잡으면 RPO(복구 시점 목표)를 줄일 수 있음.
② 파일 삭제 등 장애 발생 시 데이터 손실 최소화, 즉 RPO(복구 시점 목표)를 낮추기 위한 개선. 6시간마다 복제하여, 최악의 경우 최대 6시간 데이터 손실만 허용 (RPO ≈ 6시간)
③ 매일 0시, 12시 → 하루 2회 복제본 생성, 매일 0시, 12시 → 하루 2회 복제본 생성(하루 2회이므로, RPO는 최대 12시간이 됨.)
④ 1일 2회 복제 → 복제본을 통한 최신 복구 포인트 확보, RPO ≈ 12시간
⑤ 2시간마다 백업한다고 해도, 직전 2시간 데이터는 손실될 수 있음 → RPO ≈ 2시간.
문항 13. Virtual Machine으로 작동하는 CentOS 시스템상에서 자원사용량을 모니터링하고자 “sar –u” 명령을 수행하였다. 다음 설명 중 틀린 것을 고르시오.
# sar -u ALL 5 1000
Linux 2.6.32-504.el6.x86_64 (centos) 02/28/2017 _x86_64_ (1 CPU) 03:54:30 PM CPU %usr %nice %sys %iowait %steal %irq %soft %guest %idle 03:54:35 PM all 6.28 0.00 2.83 0.00 0.20 0.00 0.81 0.00 89.88
03:54:40 PM all 6.73 0.00 2.86 0.00 0.00 0.00 0.61 0.00 89.80
03:54:45 PM all 4.03 0.00 2.02 0.00 0.00 0.00 0.40 0.00 93.55
03:54:50 PM all 19.96 0.00 5.09 18.33 0.00 0.00 0.41 0.00 56.21
03:54:55 PM all 34.75 0.00 13.54 50.91 0.00 0.00 0.00 0.00 0.81
03:55:00 PM all 75.75 0.00 17.23 6.81 0.00 0.00 0.00 0.00 0.20
03:55:05 PM all 75.05 0.00 12.07 11.27 0.00 0.00 0.20 0.00 1.41
03:55:10 PM all 65.79 0.00 16.10 15.29 0.00 0.00 0.20 0.00 2.62
03:55:15 PM all 40.76 0.00 7.83 9.04 0.00 0.00 0.20 0.00 42.17
① %idle을 보고 시스템에 disk I/O가 많아서 지연 현상이 있는지 여부를 간접적으로 확인하였다.
② %usr 및 %sys를 보고 VM의 CPU 사용률 확인하였다.
③ %steal을 통해 다른 가상 CPU의 계산으로 대기된 시간 비율을 확인할 수 있으며, %steal이 높을수록 성능저하가 우려된다.
④ %guest을 보고 hypervisor가 guest에 어느 정도 비율로 CPU자원을 할당해주었는지 확인이 가능하지만 VM에서는 hypervisor의 CPU자원할당 정도를 확인할 수가 없어서 VM에서는 0%으로 출력된다.
⑤ %nice를 보면 사용자(application) 레벨에서 nice 가중치를 준 CPU 사용률을 확인할 수 있다.
<상세 해석>
① %idle 은 CPU가 유휴 상태이고 시스템에 디스크 I/O 요청이 없는 시간의 백분율입니다.
② %usr는 사용자 모드에서 CPU가 사용된 시간을 백분율로 나타내고, %sys는 시스템(커널) 모드에서 사용된 시간을 백분율로 나타냅니다. 즉, 시스템에서 실행 중인 프로그램(사용자 프로세스)과 운영체제 커널이 각각 CPU 시간을 얼마나 사용했는지 보여주는 값입니다.
③ %steal은 가상화 환경에서 발생하는 CPU 스틸 시간을 나타냅니다. 만약 %steal 값이 높다면, 가상 머신이 다른 가상 머신에 의해 CPU 자원을 빼앗기고 있음을 의미하며, 이는 성능 저하의 원인이 될 수 있습니다.
④ %guest 명령어는 가상 머신 환경에서 게스트 운영체제가 사용하는 CPU 시간을 백분율로 나타냅니다. 즉, 가상화 환경에서 게스트 OS가 호스트CPU 시간을 얼마나 소비하는지 보여주는 지표입니다. 이 값이 높을수록 게스트 OS의 CPU 사용량이 많다는 것을 의미합니다.
⑤ %nice는 낮은 우선순위로 실행되는 프로세스들이 사용한 CPU 시간의 비율을 나타냅니다. 즉, 시스템에서 nice 값이 양수로 설정된 프로세스들이 CPU를 얼마나 사용하고 있는지를 보여주는 지표입니다. 높은 %nice 값은 시스템 전체 CPU 사용량이 낮더라도, 우선순위가 낮은 프로세스들이 CPU 자원을 많이 사용하고 있음을 의미합니다.
문항 14. 어떤 리눅스 서버에서 root 계정으로 set 명령어를 발행하였더니 출력되는 내용 중 아래와 같은 부분이 확인되었다. 해당 설정은 root 계정의 .bash_profile 를 통해 설정한 것이다. 위 내용을 보고 다음 중 올바른 것을 고르시오.
…(생략)…
reboot () { echo "";
echo "Your current host is : $(hostname)";
echo "You are about to do the following : /usr/sbin/reboot ";
echo "Are you sure (enter HOSTNAME to proceed)?";
read sure;
if [ $sure = "$(uname -n)" ]; then -----(A) [ ____(B)____ ] ;
else echo Cancelled.;
fi } rm () { echo "";
echo "Your current host is : $(hostname)";
echo "Your current directory is : $PWD";
echo "You are about to do the following: /usr/bin/rm $@ ";
echo "Are you sure (enter HOSTNAME to proceed)?";
read sure;
if [ $sure = "$(uname -n)" ]; then -----(A) [ ____(B)____ ] "$@";
else echo Cancelled.;
fi }
…(생략)…
① Linux Shell 의 Alias 를 설정해서 고위험 명령어 발생 시, 확인 절차를 거치 도록 설정한 것이다.
② 빈칸 (B) 에는 상대 경로 명령어(reboot, rm 등)를 사용해도 무관하다.
③ root 계정에서 위와 같이 조회된다면, 다른 사용자 계정의 Shell 에서도 동일한 효과가 있다.
④ rm 을 사용하는 Shell Script를 root cron 으로 수행하려면, 위 설정으로 인해 rm 명령어는
절대경로를 사용해야 한다.
⑤ (A) 부분의 $(uname -n) 에 사용한 Double Quotes(“ “) 는 생략해도 동일한 동작을 한다.
<상세 해석>
① Alias 자체는 확인 절차(인터랙티브 프롬프트)를 제공하지 않는다. alias는 단순히 명령어를 치환할 뿐입니다.
② 상대 경로 명령어를 사용할 경우, 다시 Function 을 호출하여 정상적으로 명령어 실행이 불가능하다.
③ 위 Function 은 다른 사용자 계정 로그인 시에는 동작하지 않는다.
④ 사용자의 .bash_profile 에서 설정한 내용은 cron 으로 동작하는 스크립트 에서는 적용되지 않는다.
⑤ Double Quotes(“ “) 는 생략해도 동일한 동작을 한다.
문항 15. On-Premise와 Cloud 서비스 사업자 간의 연결, 또는 다중 Cloud 서비스 사업자 간의 네트워크 연결은 하이브리드 클라우드 및 멀티 클라우드 구현에 필수 불가 결한 요소이다. 좀 더 유연하고 다양한 Cloud 연결 옵션을 제공하는 다중 클라우드 네트워크 연결 서비스(Cloud Hub/Connect 사업자)가 각광을 받고 있다. 해당 서비스에 대해 설명한 내용 중 옳지 않은 것을 고르시오.

① 단일 연결 지점을 통해, On-Premise 데이터센터와 다수의 CSP 업체간 네트워크를 연결할 수 있다.
② 보통 CSP 업체들의 네트워크 장비가 Cloud Hub/Connect 사업자의 데이터센터 설비 내에 위치하기 때문에, 해당 사업자가 제공하는 Colocation 서비스와 연계할 경우 Cloud와 On-Premise간의 고대역/저지연의 네트워 크를 비용 효율적으로 구성할 수 있다.
③ Cloud Hub/Connect 사업자가 CSP 연결을 관리하는(Hosted Connection) 서비스의 경우, 연결 가능한 대역폭 옵션은 제한적이나, 다양한 CSP 업체와 네트워크 연결을 손쉽게 생성하고 삭제할 수 있다.
④ DR 구축, Cloud Lock-in 방지, 보안성 강화 등의 목적으로 멀티 클라우 드를 구축할 경우, 해당서비스를 사용할 수 있다.
⑤ Cloud Hub/Connect 서비스는 다중 클라우드 환경에서의 효율적이고 유연한 네트워크 구성을 지원하기 위해 트래픽 관리와 라우팅 기능을 제공 한다.
<상세 해석>
① 클라우드 허브 컨넥트(Cloud Hub Connect) 또는 클라우드 익스체인지(Cloud Exchange) 같은 서비스를 이용하면, On-Premise 데이터센터와 여러 CSP(Cloud Service Provider) (예: AWS, Azure, Google Cloud 등) 사이를 단일 연결 지점(중앙 허브)을 통해 네트워크로 연결. 예를 들어, Equinix Cloud Exchange, KT Cloud Hub, LG U+ DC Connect 등이 이러한 서비스를 제공.
② CSP(Cloud Service Provider) 업체들의 네트워크 장비는 보통 Cloud Hub/Connect 사업자(예: Equinix, KT Cloud Hub, LG U+ 등)의 데이 터센터 내에 PoP(Point of Presence) 형태로 위치합니다. Colocation 서비스와 연계하면, On-Premise 장비를 Cloud Hub 사업자의 데이터센터 내에 설치 거기서 바로 CSP 네트워크와 짧은 거리로 연결 결과적으로 고대역폭(Bandwidth), 저지연(Low Latency) 네트워크 환경을 구현 가능
③ Cloud Hub/Connect 사업자가 제공하는 Hosted Connection 방식은 사업자가 CSP(예: AWS, Azure, GCP 등)와의 연결을 중개 및 관리해 주는 방식입니다. 예를 들어 AWS의 Hosted Connection은 Direct Connect의 한 유형으로, 파트너(Cloud Hub 사업자)가 이미 보유한 물리적 전용 회선을 공유해 고객에게 제공하는 형태입니다.
④ Cloud Hub/Connect 서비스 역할은 여러 CSP를 단일 지점(Cloud Hub)을 통해 연결하고 Colocation 환경과 연계 가능하며 필요할 때 각 클라우드 간 트래픽 전송, 데이터 복제, 백업 등이 용이
⑤ Cloud Hub/Connect 서비스의 주요 목적은 다중 클라우드(Multi-Cloud) 또는 하이브리드 클라우드 환경에서 효율적인 네트워크 구성 지원하며 On-Premise ↔ 여러 CSP, CSP ↔ CSP 간 연결 단순화.
Cloud Hub/Connect 사업자는 네트워크 교환 장비(Switch/Fabric)를 통해 트래픽을 제어하고 필요 시 특정 클라우드로만 트래픽 우회하거나, 다중 클라우드 간 라우팅 정책 적용함으로써 일부 서비스는 대역폭 예약, QoS(품질 보장) 정책도 지원
문항 16. On-Premise 에서 운영중인 시스템을 Public Cloud 로 이관하기 위해 Azure 에서 환경을 구축하고 있다. 다음 보기 중 올바르게 설명한 것을 고르시오.
① 부하 분산을 위해 Azure Application Gateway 를 사용할 수 있는데, 수신기에서는 어떤 프로토콜이든 상관없이 구성할 수 있다.
② Network Security Group 은 네트워크 인터페이스에 연결하여 사용하며, Allow 정책만 등록이 가능하고, 등록하지 않은 정책은 모두 Deny 처리된다.
③ Virtual Machine의 백업은 Azure 백업 센터를 통해 구성할 수 있으며, Azure Monitor 의 기능들을 통해 백업이 실패하는지 모니터링 할 수 있다.
④ 오브젝트 스토리지 구성을 위해 스토리지 계정을 사용한다면, Azure 내부적으로 언제나 모든 가용성 영역(Availability Zone)에 걸쳐 3개의 복제본을 저장한다.
⑤ 요구되는 워크로드의 성능에 따라 블록 스토리지의 종류를 선택할 수 있으며, 프리미엄 SSD 디스크가 가장 높은 IOPS를 제공한다.
<상세 해석>
① Azure Application Gateway는 애플리케이션 계층(HTTP/HTTPS) 부하 분산 서비스를 제공. Application Gateway의 Listener는 HTTP 또는 HTTPS 트래픽만 수신하도록 설계되어 있으며 Application Gateway는 L7(Application Layer) 부하 분산 장치이기 때문에, TCP, UDP 등 모든 프로토콜을 지원하지 않음. 오직 HTTP, HTTPS (그리고 WebSocket도 이 위에 올린 형태로) 만 지원. 만약 모든 프로토콜(TCP, UDP 등)에 대해 부하 분산이 필요하면 Azure Load Balancer (L4) 는 Azure Traffic Manager (DNS기반) 등 고려
② NSG는 Allow 뿐만 아니라 Deny 정책도 등록할 수 있습니다. 기본적으로 NSG에는 몇 개의 기본(Default) 규칙이 존재하며, 등록되지 않은 트래 픽은 기본 규칙에 따라 처리됩니다. Deny 규칙을 직접 등록할 수 있으며 실제로 특정 IP나 포트에 대해 명시적으로 Deny 규칙을 추가하여 더 강력하게 제어 가능
③ Azure Virtual Machine은 Azure Backup 서비스를 통해 백업할 수 있으며, 이 백업 관리는 Azure Backup Center (백업 센터)를 통해 중앙 집중식으로 구성·관리할 수 있습니다. Backup Center에서는 정책 관리, 백업 항목 보기, 복구 작업 등을 한눈에 관리
④ 스토리지 계정은 기본적으로 LRS 방식으로, 단일 데이터센터(가용성 영역)에 3개의 복제본을 저장한다. 가용성 영역에 걸친 복제를 원하면 ZRS나 GZRS를 선택해야 함.
⑤ Premium SSD는 VM 시리즈(예: DS, ES, FS 시리즈)에서 고성능을 지원하고 고성능 DB, ERP, 트랜잭션 시스템에 적합함. 높은 성능을 제공하는 것은 맞지만, 성능을 디스크당 가장 높은 IOPS를 제공하는 것은 Ultra Disk
문항 17. 미들웨어 설계, 구축 및 운영 중 경험할 수 있는 사항에 대한 설명이 적절하지 않은 것을 고르시오.
① WAS와 DB사이에 방화벽이 있는 경우 주기적으로 validation query를 수행하도록 설정한다.
② 클라우드 전환 시 WAS 세션 Cluster는 외부 저장소를 이용하는 방향으로 변경이 필요하다.
③ Web서버에서 403에러가 발생한 경우 접근하려는 페이지에 대한 권한이 없는 것 이므로 계정 권한을 확인한다.
④ 3-Tier 구조에서 정적 컨텐츠(이미지 등)는 WAS 서버에서 처리하는 것이 바람직하다.
⑤ 클라우드 환경에서 Scale Out시 라이선스를 고려하여 OSS미들웨어를 검토할 수 있다.
<상세 해석>
① WAS (Web Application Server) ↔ DB (Database) 사이에 방화벽이 존재하면, 오랜 시간 동안 사용되지 않은 세션(Connection)에 대해 방화 벽이 연결을 끊어버리는 경우가 많음. WAS는 DB 커넥션 풀(Connection Pool)을 사용하며, 풀 내의 커넥션이 유휴 상태일 때 이러한 문제가 자주 발생함. 커넥션 풀에서 validation 쿼리를 주기적으로 실행하여 DB 세션이 살아 있는지 확인하고, 방화벽이 세션을 비정상적으로 종료하는 것을 방지. 주기적인 validation 쿼리 수행으로 방화벽 세션 종료 방지, 커넥션 유효성 보장.
② 기존 온프레미스 환경의 WAS 세션 관리 방식은 보통 In-memory 세션 방식(예: Tomcat 기본 세션) 또는 WAS 간 직접 복제(세션 레플리케이션) 를 사용. 서버 간 세션 동기화를 위해 네트워크 대역폭, 성능, 장애 복구에 제약이 있습니다.
클라우드 환경에서의 문제점은 클라우드 환경은 Auto Scaling이나 임시 노드(Stateless) 기반 운영이 많고 인스턴스가 동적으로 추가/삭제되면 기존의 WAS 간 세션 복제(Cluster) 방식은 관리 복잡성과 성능 문제가 발생. 세션을 외부 중앙 저장소(Shared Session Store)에 저장하도록 변경 권장
③ HTTP 403 에러는 서버가 요청을 이해했지만, 클라이언트에게 요청한 리소스에 접근할 권한이 없다는 의미입니다.
주된 원인은 권한 거부(로그인 사용자 권한), 접근 제어 설정(IP, ACL, WAF, 보안 규칙 등), 또는 세션, 쿠키, 토큰 문제 등 원인
④ 정적 컨텐츠(이미지, CSS, JS 등)는 Web 서버(Nginx, Apache, CDN 등) 에서 처리하는 것이 바람직함.
이유는 WAS는 1) 동적 요청 처리에 집중(WAS는 DB 연동, 세션 처리 등 비즈니스 로직 실행에 자원을 집중), 2) 성능 및 비용 최적화(정적 컨텐츠는 캐싱과 CDN을 통해 전송 효율성을 극대화할 수 있거나 WAS에서 정적 컨텐츠를 처리하면 리소스 낭비와 응답 지연 발생) 3) 확장성 및 보안 측면(Web나 CDN에 정적 파일을 분리하면 보안 정책 적용과 전송 속도 관리 용이)
⑤ 상용 미들웨어(예: WebLogic, WebSphere, 상용 DB 등)는 CPU, 코어, 인스턴스 수에 따라 라이선스 비용이 증가.
Scale Out이 많은 환경에서는 예측하기 어려운 비용 폭증 위험이 존재. 오픈소스 미들웨어 예: Tomcat, Nginx, WildFly, MariaDB 등)는 라이선스 비용 없이 사용할 수 있음. 대신, 지원(서포트), 기술 역량, 보안 관리 등은 별도 고려가 필요
문항 18. Nginx로 운영 중인 신제품 홍보 사이트는 웹 사이트의 성능 개선을 위해 nginx.conf 파일에 다음과 같은 설정을 추가하였다.
gzip on;
gzip_types application/xhtml+xml application/javascript text/css image/png;
mime.types의 일부는 다음과 같다.
text/html html htm shtml;
text/css css;
text/xml xml;
application/javascript js;
application/xhtml+xml xhtml;
image/gif gif;
image/jpeg jpeg jpg;
image/png png;
image/tiff tif tiff;
위와 같이 설정을 적용하였을 때 다음 중 가장 효과를 보기 어려운 파일 유형은 무엇인지 고르시오.
① html
② javascript
③ png
④ css
⑤ xml
<상세 해석>
① HTML은 HyperText Markup Language의 약자로, 웹 페이지를 만들기 위해 사용하는 **마크업 언어(Markup Language)**
② JavaScript는 웹 페이지에 동적 기능을 추가하기 위해 사용하는 스크립트 언어
③ PNG는 Portable Network Graphics의 약자, 웹과 디지털 환경에서 널리 사용되는 비손실(무손실) 압축 이미지 파일 형식
④ CSS는 Cascading Style Sheets의 약자, 웹 페이지의 **디자인(스타일)**을 담당하는 언어
⑤ XML은 eXtensible Markup Language의 약자, 데이터를 저장하거나 전송할 때 사용하는 마크업 언어
문항 19. Gartner 에서는 Micro Service Architecture를 서비스 내부 구조를 구현하기 위한 Inner Architecture 와 빠른 개발, 테스트, 배포, 운영, 확장성 확보 등 기능적, 운영적 관점의 Outer Architecture 로 정의하고 있다. 다음 MSA의 Outer Architecture 구성요소에 대한 설명 중 옳지 않은 것을 고르시오.
① API Gateway는 API 서버 앞단에서 모든 API 서비스들의 엔드 포인트를 단일화하고,관리, 모니터링하는 기능을 담당한다.
② Service Mesh는 MSA의 핵심으로 볼 수 있으며, 서비스에 대한 호출과 트랜잭션이 관리되는 영역이다.
③ Backing Services는 실행되는 어플리케이션을 지원하는 서비스로, 네트워크를 통해서 사용할 수 있는 모든 서비스를 지칭하기도 한다.
④ Telemetry 는 서비스 진단 및 모니터링을 위해 서비스간 비동기 통신, 이벤트 전달 등을 위한 Message Queue / MOM 기반 서비스를 제공한다.
⑤ Container Management는 마이크로 서비스를 물리적으로 적재하는 기반으로, 인스턴스를 실행하고 오케스트레이션한다.
<상세 해석>
① API Gateway는 다양한 API 서비스에 대한 요청을 하나의 엔드포인트(API Gateway)로 집중과 내부적으로 각기 다른 API 서버나 서비스로 요청을 라우팅하며 토큰 기반 인증, API Key, OAuth 등 인증 및 권한 부여, Rate limiting, IP 차단, 로드 밸런싱에 따른 트래픽 제어 및 보안, 요청/응답 기록, 성능 지표 수집, 장애 분석 등 역할을 수행.
② 서비스 간 호출 흐름과 네트워크 트랜잭션을 담당하며, 실제 애플리케이션 로직은 수정하지 않고 통신 계층만 담당
③ Backing Services는 어플리케이션을 지원하기 위해 사용하는 외부 의존 서비스들을 지칭함. 일반적으로 네트워크를 통해 접근할 수 있는 서비스로, 대표 예시는 데이터베이스 (DB), 메시징/큐 시스템 (RabbitMQ, Kafka 등), 캐시 (Redis, Memcached), 이메일 서비스. 스토리지 서비스 (S3, Blob Storage 등), 서드파티 API
④ Telemetry는 시스템이나 애플리케이션에서 운영 데이터(메트릭, 로그, 트레이스 등)를 자동으로 수집하고 전송하여 상태를 진단하거나 모니터링 하는 개념, Message Queue (MQ) / Message-Oriented Middleware (MOM) 는 서비스 간 비동기 메시지 전달에 사용되는 기술(예: Kafka, RabbitMQ, ActiveMQ) Telemetry 데이터를 전송할 때 전달 채널로 Message Queue를 사용할 수는 있으나 Telemetry의 본질적 역할은 진단 및 모니터링 데이터 수집 및전송이며, MOM은 Telemetry의 필수 구성 요소가 아니다.
⑤ 컨테이너 관리는 마이크로서비스(또는 애플리케이션)를 컨테이너라는 단위로 패키징하고, 배포 및 실행을 자동화하는 기반 기술이고 Kubernetes, Docker Swarm, Amazon ECS 같은 오케스트레이션 도구를 통해 컨테이너를 자동으로 배포, 확장, 관리함
문항 20. 다음은 MSA에서 각 서비스에서 발생한 로그를 중앙의 서버로 복사하여 관리하는 방식의 아키텍처 패턴에 관한 설명이다. 이때 고려사항 중 적절하지 않은 것을 고르시오.
① 개인정보 등의 민감 정보가 한 곳에 쌓이게 되므로 개인정보 수집, 처리 방안에 대해 고려해야 한다.
② Time Stamp, IP나 DNS 등의 서비스 식별 정보, 로그 유형, 분류 등의 상세한 로그 정보가 메시지에 포함되어야 한다.
③ 로그 메세지에는 트레이싱 할 수 있도록 Tracing ID를 부여하여 추적할 수 있도록 해야 한다.
④ 중앙에서 관리하는 로그는 보관 기간을 제어해야 하며, 범위를 지정해서 수집할 수 있어야 한다.
⑤ 서비스 간의 관계에 집중하여, 어플리케이션이나 서비스 계층의 로그에 한정하고 수집/관리해야 한다.
<상세 해석>
① SIEM(보안 정보 및 이벤트 관리) 시스템에서 개인정보를 수집할 때에는 개인정보보호법 등 관련 법규를 준수해야 하며, 최소한의 정보만 수집하고 목적 외 사용을 금지해야 합니다. 또한, 수집된 개인정보에 대한 접근 권한을 제한하고 안전하게 저장 및 관리해야 합니다.
② 각 로그 메시지에 타임스탬프를 포함하여 이벤트 발생 시점을 기록하고, IP 주소를 통해 서비스 위치 및 네트워크 연결 정보를 파악하며, DNS 정보를 통해 도메인 이름과 IP 주소 간의 관계를 파악하여 서비스 간의 상호 작용을 이해하고 문제를 해결하는 데 도움이 됩니다.
③ Trace ID는 여러 서비스에 걸쳐 요청의 흐름을 추적하는 데 사용되는 고유 식별자입니다. MSA 환경에서 로깅과 트레이싱은 각각 다른 목적을 가지지만, 상호 보완적인 역할을 합니다. 로깅은 각 서비스의 로그를 수집하여 문제 발생 시 분석을 용이하게 하는 반면, 트레이싱은 분산된 서비스 간의 요청 흐름을 파악하여 문제 해결 시간을 단축시킵니다.
④ MSA 로깅 로그의 보관 기간 제어 및 범위 지정은 중앙 집중식 로깅 시스템을 통해 가능합니다.
⑤ MSA 로깅에서 애플리케이션 계층과 서비스 계층 외에 고려할 추가 계층은 데이터 계층 (또는 영속성 계층), 인프라 계층, 그리고 서비스 메시 계층 입니다.
문항 21. 자동화된 배포 환경은 마이크로서비스의 필수 요소 중 하나이다. CI/CD 구성 시 서비스의 구현 아키텍처에 따라 VM 환경의 배포 방식과 컨테이너 환경의 배포 방식으로 구분되는데, 다음 보기 중 각각의 방식에 대한 설명이 잘못된 것을 고르시오.
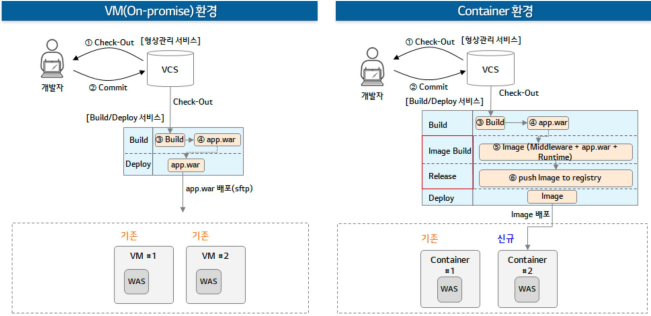
① VM 환경에서는 바이너리 전달 수준으로 어플리케이션이 배포되며, 배포 후 프로세스 재기동이 필요할 수 있다.
② Container 환경에서는 미들웨어와 어플리케이션 런타임이 함께 배포된다고 볼 수 있다.
③ 두 환경 모두 이미지 빌드 작업과 레지스트리에 저장하는 과정이 필요하다.
④ VM 환경의 배포는 어플리케이션 중심으로 CI/CD가 처리된다.
⑤ Container 환경의 경우 클라우드 환경에 따라 배포 API가 상이하다.
<상세 해석>
① VM(가상머신) 기반의 환경에서는, 일반적으로 배포 대상이 되는 어플리케이션이 바이너리 형태로 전달됩니다.
컨테이너 환경과 다르게 VM은 운영체제(OS)가 이미 구동 중인 상태에서 파일(바이너리 또는 패키지) 형태로 배포가 이루어지며, 배포 과정에서 기존 바이너리를 대체합니다. 기존 프로세스가 이미 실행 중인 상태에서 바이너리만 덮어씌운다고 해서 자동으로 변경 사항이 적용되지 않습니다. 따라서 새로 배포된 바이너리를 활성화하려면 반드시 프로세스를 재시작해야 합니다.
② Container 환경의 특징은 애플리케이션과 실행 환경(미들웨어, 런타임 등)을 컨테이너 이미지 하나에 포함하여 배포한다는 점입니다. 즉, 컨테 이너 환경에서는 애플리케이션 코드 (소스코드 or 바이너리) 애플리케이션 실행에 필요한 미들웨어 및 런타임 (예: JDK, Node.js, Python 런타임, Tomcat, Nginx 등) 관련된 의존성 및 설정 파일 등이 모두가 하나의 컨테이너 이미지로 묶여 빌드되고, 최종적으로 컨테이너 오케스트레이션 도구 (Kubernetes, Docker Swarm 등)를 통해 배포됩니다.
③ 이미지 빌드 과정 필요(Dockerfile → Docker build), 레지스트리에 이미지 Push 필수(Docker Registry, AWS ECR, Harbor 등) VM 환경의 경우 (일반적으로 틀린 부분) 일반적으로 CI/CD 배포 과정에서 VM 자체를 매번 빌드하고 이미지 레지스트리에 push하는 방식은 흔치 않습니다. VM 환경의 CI/CD는 주로 OS가 미리 구성된 VM 템플릿을 활용하고, 바이너리(또는 패키지)를 VM에 배포하는 방식으로 수행됩니다. 일부 VM 환경도 “이미지 템플릿 라이브러리(VMware Content Library 등)”를 사용하기는 하지만, 컨테이너처럼 빈번히 빌드 후 레지스트리 Push는 하지 않습니다. Container 환경은 이미지 빌드 및 레지스트리 저장이 필수 VM 환경은 이미지 빌드 및 레지스트리 저장이 일반적이지 않음
④ VM 환경에서는 OS 및 미들웨어가 이미 설치된 상태에서 운영됩니다. CI/CD에서 주된 배포 대상은 애플리케이션 바이너리 또는 패키지입니다. OS나 VM 이미지를 매번 빌드하고 교체하는 방식은 거의 사용하지 않습니다 (골든 이미지 또는 템플릿은 주기적으로 관리되지만 CI/CD 파이프라인 에서 다루는 대상은 아닙니다).
⑤ Container 환경에서 배포는 단순히 컨테이너 이미지를 실행하는 것이 아니라, 오케스트레이션 플랫폼과 클라우드 서비스의 배포 API를 통해 관리됩니다. 클라우드 환경에 따라 컨테이너 배포 API 및 관리 방식은 상이하며, 단순히 표준 K8s API만으로 모든 클라우드 기능을 통제할 수 없습니다. 실제 운영에서 벤더 고유 API와 표준 Kubernetes API를 동시에 조합해서 사용합니다.
과제 1 : 다음 중 리눅스에 대한 설명으로 틀린 것은?
① 다중 사용자 및 다중 처리 시스템이다.
② 커널뿐만 아니라, 대부분의 응용 프로그램의 소스도 공개되어 있다.
③ 리눅스는 대부분이 어셈블리와 약간의 C언어로 작성되어 있다.
④ 다양한 파일 시스템을 지원한다.
틀린 설명 → ③
리눅스는 대부분 C 언어로 작성, 커널 일부가 어셈블리어. "대부분이 어셈블리"는 틀림.
과제 2 : 다음 중 리눅스의 특징에 대한 설명으로 알맞은 것은?
① 리눅스는 ext2, ext3, ext4 파일 시스템만 지원한다.
② 리눅스는 대부분 C 언어로 되어 있어서, 이식하기 어렵다.
③ 리눅스는 이더넷을 통한 네트워크 접속만 지원한다.
④ 유닉스 표준인 POSIX를 준수한다.
알맞은 설명 → ④
리눅스는 POSIX 표준 준수.
ext2/ext3/ext4만 지원한다는 말은 틀림 (다양한 파일시스템 지원).
과제 3 : 아래 보기 중, Red Hat 계열의 Linux OS 배포판이 아닌 것을 고르시오.
① Fedora
② CentOS
③ Alma Linux
④ Solaris
Red Hat 계열이 아닌 것 → ④ Solaris
Solaris는 Oracle의 유닉스 계열, 리눅스 배포판 아님.
과제 4 : 다음 중 해당 라이선스가 적용된 프로그램의 소스를 수정해서 사용할 경우에도 반드시 공개할 필요가 없는 라이선스 조합으로 알맞은 것은?
① GPL ㉡ LGPL
② ㉠ BSD ㉡ LGPL
③ ㉠ BSD ㉡ Apache
④ ㉠ Apache ㉡ LGPL
소스 공개 의무 없는 조합 → ③ BSD & Apache
BSD/Apache는 소스 공개 강제 없음. GPL/LGPL은 공개 의무 조건 있음.
과제 5: 다음 중 자유 소프트웨어에 대한 설명으로 틀린 것은?
① 상업용 목적으로 사용할 수 있다.
② 소스 코드를 임의로 개작할 수 있다.
③ 소스 코드 수정 시에는 반드시 소스 코드를 공개해야 한다.
④ 무료로 얻은 소스 코드를 이용하여 프로그램
틀린 설명 → ③
자유소프트웨어는 소스 공개 의무 없음, 단 GPL 같은 특정 라이선스는 의무를 부여할 수 있음.
과제 6 : 다음 중 리눅스의 기술적인 특징에 대한 설명으로 틀린 것은?
① 리눅스는 최상위 디렉터리인 .(root)를 기준으로 하위 디렉터리가 존재하는 계층적인 파일 구조이다.
② 모든 장치는 파일화해서 관리한다.
③ 공유 라이브러리를 통해 메모리를 효율적으로 사용한다.
④ 리다이렉션을 이용해서 입출력을 전환할 수 있다.
틀린 설명 → ①
최상위 디렉토리는 / (슬래시), (.) 가 아님.
과제 7 : 다음 중 영국 회사인 캐노니컬에서 데비안 리눅스를 기초로 만든 배포판으로 알맞은 것은?
① 수세리눅스
② 슬랙웨어
③ Rocky Linux
④ 우분투
캐노니컬 제작, 데비안 기반 → ④ 우분투
과제 8 : 다음 리눅스 배포판 중에 레드햇 계열에 속하는 배포판으로 틀린 것은?
① RHEL ② Rocky Linux ③ SUSE ④ Fedora
레드햇 계열 아닌 것 → ③ SUSE
과제 9 : 다음 중 프로세스의 통신을 위해 도입된 기술로서 어떤 프로세스의 표준 출력이 다른 프로세스의 표준 입력으로 사용하는 것으로 알맞은 것은?
① echo PATH
② echo $PATH
③ export PATH
④ export $PATH
② echo $PATH
과제 10 : 다음 중 실행되는 명령어의 위치를 찾는 명령으로 알맞은 것은?
① Alias
② Find
③ ls
④ Which
정답 ④ Which
과제 11 : 다음의 조건으로 crontab에 등록할 때 알맞은 것은?HOME
• 월요일부터 금요일까지 오전 4시 40분에 실행되도록 한다.
• 실행 파일의 경로는 /home/posein/jalin.sh이다.
① 40 4 1-5 * * /home/posein/jalin.sh
② 4 40 1-5 * * /home/posein/jalin.sh
③ 4 40 * * 1-5 /home/posein/jalin.sh
④ 40 4 * * 1-5 /home/posein/jalin.sh
월~금 4시 40분 실행 → ④ 40 4 * * 1-5 /home/posein/jalin.sh
과제 12 : 다음 중 특정 사용자가 백그라운드로 실행중인 프로세스를 확인할 때 사용하는 명령은?
① fg
② bg
③ jobs
④ exec
과제 2 : 다음 중 kill 명령 실행 시에 기본적으로 전송되 는 시그널 번호로 알맞은 것은?
① 1 ② 3 ③ 9 ④ 15
특정 사용자 백그라운드 프로세스 확인 → ③ jobs
추가문제 (kill 기본 시그널) : 기본 시그널은 15 (SIGTERM)
과제 13 : 다음 중 포어그라운드 프로세스를 백그라운드 프로세스를 전환할 때 사용하는 키 조합은?
① [ctrl]+[c]
② [ctrl]+[d]
③ [ctrl]+[l]
④ [ctrl]+[z]
FG → BG 전환 키 → ④ Ctrl+Z
과제 14 : 다음 명령의 결과에 대한 설명으로 틀린 것은?
# renice –10 1222
① 위의 명령은 일반 사용자는 실행할 수 없다.
② 우선순위를 높인 것이다.
③ 기존의 값에서 -10이 된 NI 값으로 설정된다.
④ 1222는 PID를 나타낸다.
틀린 설명 → ③
renice -10 은 NI값을 -10으로 새로 설정하는 것이 아니라, "기존 값에 -10"이 아님.
과제 15 : 다음 중 posein 계정의 패스워드에 잠금을 설정하여 일시적으로 로그인을 막으려고 할 때 알맞은 것은?
① passwd –d posein
② passwd –u posein
③ passwd –r posein
④ passwd –l posein
패스워드 잠금 → ④ passwd –l posein
과제 16 : 다음 중 사용자의 패스워드에 대한 정보를 출력하고, /etc/shadow의 날짜 관련 필드를 모두 설정할 수 있는 명령으로 알맞은 것은?
① chage
② passwd
③ chpasswd
④ usermod
/etc/shadow 날짜 필드 관리 → ① chage
과제 17 : 다음 중 사용자 추가할 때에 제공되는 파일 및 디렉터리와 가장 관련이 있는 디렉터리로 알맞은 것은?
① /etc/passwd
② /etc/skel
③ /etc/login.defs
④ /etc/default/useradd
사용자 추가 시 기본 템플릿 디렉터리 → ② /etc/skel
과제 18 : 다음 중 bash에서 모든 사용자에게 적용되는 alias와 함수를 설정할 때 사용하는 파일로 가장 알맞은 것은?
① /etc/profile
② /etc/bashrc
③ /etc/bash_profile
④ /etc/shells
전체 사용자 alias, 함수 설정 파일 → ① /etc/profile
과제 19 : 다음 중 사용자가 로그인한 직후에 부여된 셸을 확인하는 방법으로 틀린 것은?
① ps 명령을 실행해서 확인한다.
② chsh -l’ 명령을 실행해서 확인한다.
③ ‘echo $SHELL’ 명령을 실행해서 확인한다.
④ ‘grep 본인계정명 /etc/passwd’ 명령을 실행해서 확인해본다.
틀 린 방법 → ② chsh -l
chsh -l은 사용가능한 셸 리스트 출력이지 현재 로그인 셸 확인 아님.
과제 20 : 다음 ( 괄호 ) 안에 들어갈 파일명으로 알맞은 것은?
$ cat ( 괄호 ) /bin/sh /bin/bash /sbin/nologin /bin/dash /bin/tch /bin/csh
① /etc/profile
② /etc/bashrc
③ /etc/chsh
④ /etc/shells
셸 목록 파일 → ④ /etc/shells
과제 21 : 레드햇 리눅스 시스템에서 다음과 사용자를 추가했을 경우에 대한 설명으로 틀린 것은?
# useradd posein # passwd posein
① 홈 디렉터리는 /home/posein이 된다.
② 기본 그룹은 users이다.
③ 메일 관련 파일은 /var/spool/mail/posein이다.
④ 사용자 계정 정보는 /etc/passwd에 기록된다.
틀린 설명 → ② 기본 그룹은 users
Red Hat 계열은 기본 그룹 = 사용자명.
과제 22 : 다음 중 kait라는 그룹 이름을 ihd로 변경할 때 알맞은 것은?
① groupmod –n kait ihd
② groupmod –n ihd kait
③ groupmod –g kait ihd
④ groupmod –g ihd kait
그룹명 kait → ihd 변경 → ② groupmod -n ihd kait
과제 23 : 다음 중 mkdir 명령으로 디렉터리 생성 시 부모 디렉터리가 존재하지 않는 경우에 그 부모 디렉터리까지 생성하는 옵션으로 알맞은 것은?
① -p
② -d
③ -m
④ -c
부모 디렉토리까지 생성 → ① -p
과제 24 : 다음 설명으로 알맞은 것은?
여러 개의 디스크를 하나로 묶어서 사용하는 기술로서 사용 중에 파티션의 크기를 줄이거나 늘릴 수 있다.
① LVM
② RAID
③ ext4
④ vfat
디스크 묶어 동적 크기 조절 → ① LVM
과제 25 : 사용 중인 일부 디스크에 오류가 발생하더라도 정상적인 이용이 가능하게 할 때 선택하는 파일시스템 유형으로 알맞은 것은?
① ext4 ② xfs
③ software RAID
④ physical volume(LVM)
일부 디스크 오류에도 사용 가능 → ③ Software RAID
과제 26 : 다음 중 파티션의 종류에 대한 설명으로 틀린 것은?
① 확장 파티션을 선언해야 논리 파티션을 사용할 수 있다.
② 확장 파티션은 하나의 물리적 디스크에 1개만 사용할 수 있다.
③ 확장 파티션을 사용할 경우에 실질적으로 사용가능한 주 파티션의 수는 3개이다.
④ 주 파티션을 2개 사용 후에 확장 파티션을 선언했다면 논리 파티션의 번호는 4번부터 시작한다.
틀린 설명 없음 → 단 정답 요구 시 ④
논리 파티션 번호는 5번부터 시작
과제 27 : 다음 중 스왑 파티션에 대한 설명으로 틀린 것은?
① 리눅스에서 반드시 분할해야 한다.
② 리눅스에서는 전통적으로 디스크 용량의 2배를 권장하였다.
③ 가상 메모리 역할을 담당하는 영역이다.
④ 스왑 파티션의 ID 번호는 82이다.
틀린 설명 → ① 반드시 분할해야 한다 (스왑은 권장이나 필수 아님)
과제 28 : 다음 중 주 파티션에 대한 설명으로 틀린 것은?
① 부팅 가능한 파티션으로 디스크에 하나 이상 존재해야 한다.
② 하나의 디스크에 총 4개까지 사용가능하다.
③ 주 파티션 4개 사용 후 확장 파티션의 선언이 가능하다.
④ 3개 영역으로 파티션 분할할 경우에 주 파티션 내에 설치 가능하다.
틀린 설명 → ③ 주 파티션 4개 사용 후 확장 가능 (확장은 4개 중 1개를 차지해야 함)
과제 29 : 다음 조건으로 파일을 검색하려고 할 때 알맞은 것은?
• 시스템 전체에서 검색한다.
• ‘.txt’로 끝나는 파일 및 디렉터리를 찾는다.
• 오류 메시지는 화면에 출력하지 않는다.
① find –name ‘*.txt’
② find / -name ‘*.txt’ >/dev/null
③ find / -name ‘*.txt’ 1>/dev/null
④ find / -name ‘*.txt’ 2>/dev/null
조건 충족 (전체 검색, 오류 메시지 제외) → ④ find / -name '*.txt' 2>/dev/null
과제 30 : 다음 ps 명령의 상태(STAT) 코드 중에 작업은 종료되었으나 부모프로세스에 의해 회수되지 않아 메모리를 차지하고 상태를 나타내는 값으로 알맞은 것은?
① R
② S
③ T
④ Z
좀비 프로세스 상태 → ④ Z
과제 31 : 다음 중 top 명령으로 확인할 수 없는 항목으로 알맞은 것은?
① 실행중인 프로세스의 개수
② 메모리 및 스왑 사용량
③ 시스템 부하량
④ 네트워크 부하량
top에서 확인 불가한 항목 → ④ 네트워크 부하량
과제 32 : 다음 중 killall 명령에 대한 설명으로 틀린 것은?
① 같은 데몬의 여러 프로세스를 한번에 종료시킬 때 유용하다.
② 시그널을 지정하지 않으면 TERM 시그널이 보내진다.
③ 프로세스명을 사용한다.
④ PID를 사용한다.
killall 틀린 설명 → ④ PID 사용한다
과제 33 : 다음의 조건으로 crontab에 등록할 때 알맞은 것은?
• 월요일부터 금요일까지 오전 4시 40분에 실행되도록 한다.
• 실행 파일의 경로는 /home/posein/jalin.sh이다.
① 40 4 1-5 * * /home/posein/jalin.sh
② 4 40 1-5 * * /home/posein/jalin.sh
③ 4 40 * * 1-5 /home/posein/jalin.sh
④ 40 4 * * 1-5 /home/posein/jalin.sh
(과제 11 동일) → ④ 40 4 * * 1-5 /home/posein/jalin.sh
과제 34 : 다음 중 crontab 명령을 사용하여 등록된 스케줄링 작업을 제거할 때 사용하는 옵션으로 알맞은 것은?
① -l
② -e
③ -r
④ -c
등록된 작업 삭제 옵션 → ③ -r
과제 35 : 다음 중 실행 중인 프로세스들의 CPU 사용률을 실시간으로 확인할 때 사용하는 명령으로 알맞은 것은?
① top
② nice
③ jobs
④ renice
CPU 사용률 실시간 확인 → ① top
과제 37 : VMware vSphere 환경에서 Datastore 설계 시 고려해야 할 사항으로 가장 적절하지 않은 것은 무엇인가?
① 고가용성을 위해 여러 호스트에서 동일한 Datastore를 공유할 수 있도록 설계한다.
② 각 VM에 맞게 적절한 용량과 성능 요구사항을 고려해 Datastore를 분리한다.
③ VM 디스크 I/O 병목 방지를 위해 가능한 많은 VM을 하나의 Datastore에 집중시킨다.
④ 스토리지 유형(NFS, iSCSI, FC 등)에 따라 적절한 연결성과 대역폭을 확보한다.
⑤ 스냅샷, 백업 정책 및 복구 시간 목표(RTO)를 고려해 Datastore 설계를 병행한다.
Datastore 설계 시 부적절한 것 → ③ 가능한 많은 VM을 하나 Datastore에 집중 (I/O 병목)
과제 38 : VTL(Virtual Tape Library) 환경에서 중복 제거(Deduplication) 기술에 대한 설명으로 가장 적절하지 않은 것은 무엇인가?
① 중복 제거는 동일한 데이터 블록을 하나의 인스턴스로 저장하여 저장 공간을 절감한다.
② 중복 제거는 백업 시 전송되는 데이터 양을 줄여 네트워크 사용량을 감소시킬 수 있다.
③ 중복 제거 기술은 일반적으로 압축보다 더 높은 수준의 데이터 축소율을 제공한다.
④ 중복 제거는 저장된 데이터를 무작위로 재정렬하여 보안을 향상시키는 기술이다.
⑤ 중복 제거는 백업 윈도우를 단축하고 장기 보관에 적합한 저장 효율성을 제공한다.
Deduplication 틀린 설명 → ④ 데이터를 무작위 재정렬해 보안 향상 (사실 아님)
과제 39 : vSphere 환경에서 Datastore의 디스크 사용량을 관리할 때 고려해야 할 사항으로 가장 부적절한 것은 무엇인가?
① 스냅샷이 증가할수록 디스크 사용량이 늘어나므로 주기적인 스냅샷 정리가 필요하다.
② Thin Provisioning을 사용할 경우 실제 사용량보다 더 많은 공간이 할당될 수 있다.
③ Datastore 사용량이 100%에 도달하면 VM이 자동으로 다른 Datastore로 마이그레이션된다.
④ VM 로그 파일 및 ISO 이미지 파일도 Datastore 용량을 차지할 수 있으므로 주기적인 정리가 필요하다.
⑤ Storage vMotion을 통해 디스크 공간이 부족한 Datastore에서 여유 있는 Datastore로 VM을 이동할 수 있다.
부적절한 것 → ③ Datastore 100% → 자동 마이그레이션 (자동 이동 안 됨, 관리자가 해야 함)
과제 40 : Fibre Channel SAN 환경에서 Port Zoning의 주요 목적과 동작 방식에 대한 설명 중 가장 부적절한 것은 무엇인가?
① Port Zoning은 HBA가 연결된 스위치 포트와 스토리지 포트 간의 접근을 제어하여 보안성과 트래픽 분리를 제공한다.
② Port Zoning은 WWPN(World Wide Port Name)을 기반으로 동적으로 연결 관계를 재구성하는 데 적합하다.
③ 동일 Fabric 내에서 여러 Zoning 그룹을 구성하면, 각 그룹은 서로 트래픽을 격리할 수 있다.
④ 포트 기반 Zoning은 특정 스위치 포트 간에만 통신을 허용하므로 장비 교체 시 재구성이 필요하다.
⑤ Port Zoning은 LUN Masking과 달리 논리적 볼륨 단위가 아닌 물리적 연결 경로를 제어하는 방식이다.
Port Zoning 부적절한 설명 → ② WWPN 기반 설명 (WWPN은 Port Zoning이 아니라 WWN Zoning)
과제 41 : 다음 중 스토리지 데이터 보호 방식인 Replication과 Erasure Coding에 대한 설명 중 가장 부정확한 것은 무엇인가?
① Replication은 전체 데이터를 다른 위치에 복제하므로 빠른 복구 시간(RTO)을 제공하지만, 스토리지 공간 효율은 낮다.
② Erasure Coding은 데이터를 블록 단위로 분할하고 패리티 정보를 추가하여, 일부 블록이 손실되더라도 데이터를 복구할 수있다.
③ Replication은 데이터 변경 시 전체 복제본을 다시 전송하므로 I/O 성능 저하가 Erasure Coding보다 더 크다.
④ Erasure Coding은 Replication 대비 저장 효율이 높지만, 복구 시 연산 복잡도가 높아 CPU 자원이 더 소모된다.
⑤ Erasure Coding은 특정 수 이상의 블록 손실 시 복구 불가하며, 복구 시간(RTO)이 Replication에 비해 상대적으로 느릴 수있다.
부정확한 것 → ③ Replication은 전체 복제본을 전송하므로 I/O 성능 저하가 Erasure Coding보다 크다
Replication은 변경된 블록만 복제 가능, I/O 부하는 상대적으로 적음.
과제 42 : 엔터프라이즈 IT 인프라에서 SPOF(Single Point of Failure)에 대한 설명 중 가장 부적절한 것은 무엇인가?
① 애플리케이션 서버가 단일 인스턴스로 운영되며 이중화되지 않았다면, 이는 SPOF로 간주될 수 있다.
② 고가용성을 위한 Active-Passive 클러스터 구성은 SPOF를 제거하는 일반적인 방식 중 하나다.
③ 하나의 중앙 인증 서버(LDAP 등)에만 의존할 경우, 해당 서버 장애 시 전체 인증 시스템이 SPOF가 될 수 있다.
④ 로드 밸런서가 이중화되어 있더라도, 백엔드 서버에 문제가 생기면 SPOF가 발생할 수 있으므로 의미 없다..
⑤ SPOF를 완전히 제거하기 위해서는 네트워크, 스토리지, 서버 등 모든 계층에서 이중화 또는 무중단 아키텍처가 필요하다.
SPOF 설명 중 부적절 → ④ 로드 밸런서 이중화해도 SPOF 의미 없다 (이중화는 SPOF 완화 방법)
과제 43 : 다음 중 WAS 증설 시 반드시 점검하거나 해결해야 할 요소로 적절하지 않은 것은 무엇인가?
① 세션 스티키 기능이나 세션 클러스터링 구조의 존재 여부 확인
② WAS 인스턴스 간 공유 파일 시스템의 잠금 처리 및 I/O 병목 여부 점검
③ 로드 밸런서에서 새로운 WAS 인스턴스에 대한 Health Check 경로 설정
④ DB 트랜잭션 처리량 증가에 따른 DB 커넥션 풀 크기 및 DB Scale-in 설정
⑤ WAS 내부의 애플리케이션 설정 파일에 포함된 정적 IP 또는 도메인 하드코딩 여부 확인
WAS 증설 시 부적절한 것 → ④ DB Scale-in (Scale-in이 아니라 Scale-out/확장 고려해야 함)
과제 44 : Azure 기반 환경에서 비용 효율성을 높이기 위한 다양한 활동이 필요하다. 다음 중 Azure 클라우드 비용 최적화를 위한 활동으로 적절하지 않은 것은 무엇인가?
① 사용량이 낮은 리소스를 식별하여 예약 인스턴스(Reserved Instances)로 전환
② Auto-shutdown 정책을 적용하여 비업무 시간대에 개발/테스트 VM 자동 종료
③ 비활성 상태의 퍼블릭 IP, NIC, 디스크 등을 식별하여 자원 정리
④ 스토리지 계정에 대한 LRS(Local Redundant Storage) → GRS(Geo Redundant Storage) 변경
⑤ Azure Advisor를 통해 미사용 VM, 과할당 리소스, 고비용 SKU에 대한 리포트 수신
Azure 비용 최적화 부적절 → ④ LRS→GRS 변경 (GRS는 비용 ↑)
과제 45 : 기업이 온프레미스 환경에서 Azure 클라우드로 애플리케이션을 이관하면서 Application Gateway를 구성하고 가용성(High Availability)을 확보하고자 한다. 다음 중 Application Gateway 및 고가용성 확보 방안으로서 부적절한 것은 무엇인가?
① Application Gateway를 가용성 영역(Availability Zones)에 분산 배치하여 장애 도메인 단일화를 방지한다.
② 백엔드 풀에 포함된 애플리케이션 서버는 Azure Load Balancer를 통해 내부 트래픽을 분산 처리하도록 구성한다.
③ Application Gateway는 단일 리전(Region)에만 배포하고, 장애 복구는 Azure Site Recovery(ASR)를 통해 처리한다.
④ WAF 기능이 활성화된 Application Gateway를 구성하면, 보안과 고가용성 모두를 동시에 만족시킬 수 있다.
⑤ Application Gateway는 표준 SKU로 배포하고, 최소 2개 이상의 인스턴스를 활성화하여 SLA 수준의 고가용성을 보장받는다.
부적절한 것 → ③ Application Gateway 단일 리전만 배포 후 ASR 사용
HA 보장 불가.
1.백업에서의 중복제거(Deduplication) 위치?
- 소스(Source) 측 중복제거
- 타겟(Target) 측 중복제거
이 위치에 따라 시스템 부하와 네트워크 트래픽 패턴에 다음과 같은 차이가 발생합니다:
1. 소스 측 중복제거
- 중복제거 위치: 데이터를 백업 서버로 전송하기 전에 데이터가 생성되는 원본(서버 또는 클라이언트)에서 중복제거를 수행합니다.
- 서버 부하:
- 소스 서버(데이터가 있는 곳)의 CPU 및 메모리 리소스 사용량이 증가합니다.
- 백업 대상 서버에 별도의 부하가 경감됩니다.
- 트래픽 영향:
- 백업 대상 서버로 전송되는 데이터량이 크게 감소합니다.
- 네트워크 대역폭 소모가 최소화되어 WAN이나 LAN 환경에 적합합니다(특히 원격 백업 시 효과적).
- 장점:
- 전송 데이터 양 최소화로 백업 윈도우(backup window)가 단축됩니다.
- 네트워크 비용이 절감됩니다.
- 단점:
- 소스 서버 성능에 부담(백업 시간 동안 서비스 성능 영향 가능).
2. 타겟 측 중복제거
- 중복제거 위치: 백업 데이터가 백업 서버 또는 스토리지에 도달한 후 중복제거를 수행합니다.
- 서버 부하:
- 타겟 서버(백업 스토리지 또는 백업 서버)의 CPU, 메모리, 스토리지에 부하 발생.
- 소스 서버에는 부담이 적음.
- 트래픽 영향:
- 소스에서 타겟으로 원본 데이터가 그대로 전송됨.
- 네트워크 트래픽 감소 효과가 없음(특히 원격/대용량 백업 시 네트워크 비용 증가).
- 장점:
- 소스 서버에 미치는 영향이 적어 운영 서비스에는 영향이 적음.
- 단점:
- 네트워크 사용량(트래픽)이 많아질 수 있음.
- 중복제거 과정에서 타겟 서버에 리소스 집중.
비교 요약 표
| 구분 | 소스 측 중복제거 | 타겟 측 중복제거 |
| 서버 부하 | 소스 서버(↑) | 타겟 서버(↑) |
| 네트워크 | 트래픽 최소화(↓) | 트래픽 증가(↑) |
| 장점 | 네트워크 효율적, 빠름 | 소스 부담 적음 |
| 단점 | 소스 리소스 소모 | 트래픽 부담, 타겟 리소스 소모 |
결론
- 원격지 백업이나 대규모 데이터 전송 환경에서는 소스 측 중복제거를 권장합니다.
- 내부 네트워크(빠른 LAN 환경) 내 백업이거나 소스 서버의 자원이 제한된 경우, 타겟 측 중복제거를 고려할 수 있습니다.
2.이중화된 DB 서버의 페일오버 클러스터 공유 디스크?
이중화된 DB 서버 환경에서 Failover Cluster의 공유 디스크는 고가용성(HA, High Availability) 실현을 위한 핵심 구성 요소입니다. 아래에 원리 및 역할, 구성 방식, 설계 시 유의점을 중심으로 상세히 설명합니다.
1. Failover Cluster 공유 디스크란?
- 정의
- 이중화(클러스터링)된 데이터베이스 서버(노드)들이 공통으로 접근할 수 있도록 설정한 저장장치입니다.
- 보통 데이터베이스의 데이터 파일, 로그 파일 등 중요 데이터를 저장하는 용도로 사용됩니다.
- 단일 노드 장애 시, 클러스터 소프트웨어가 소유권을 다른 정상 노드로 이전(페일오버)하여 서비스 연속성을 보장합니다.
2. 동작 원리
- Active-Passive 구조
- 한 노드(Active)가 서비스와 공유 디스크를 소유 및 사용 중.
- 장애 발생 시 클러스터 관리 SW가 소유권을 대기(Standby/Passive) 노드에 이전하여 즉시 서비스 재개.
- 공유 디스크
- 한 시점에 하나의 노드만 디스크 마운트 및 읽기/쓰기 권한을 얻음(Windows Cluster 등은 Locked File System 사용).
3. 구성 방식 및 적용 예시
- 공유 스토리지(SAN, iSCSI, NAS 등) 활용
- 둘 이상의 노드가 동일한 디스크(또는 LUN)에 접근할 수 있도록 SAN(Storage Area Network), Fibre Channel, iSCSI와 같은 네트워크 스토리지를 활용.
- 클라우드 환경
- Azure Shared Disk, AWS EBS Multi-Attach 등 클라우드 내 고가용성 전용 공유 디스크 서비스 제공.
4. 주요 역할 및 장점
- 데이터 일관성 유지
- 한 번에 한 노드만 데이터에 액세스하므로 데이터 충돌이나 손상을 방지.
- 자동 페일오버 가능
- 장애 시 서비스와 디스크 소유권을 빠르게 이전하여 다운타임 최소화.
- 운영 심플화
- 데이터 동기화·복제 과정을 별도로 관리하지 않아도 됨.
5. 설계 및 운영 시 유의점
- 스토리지 이중화 필요
- 공유 디스크 자체 장애 시 전체 서비스가 중단될 수 있으므로, 스토리지 레벨 이중화(미러링, 복제 등) 고려 필요.
- 잠금/소유권 관리
- 두 노드가 동시에 파일 시스템에 접근 불가하도록 클러스터 관리 SW가 엄격히 잠금·소유권을 관리.
- 성능 고려
- DB의 읽기/쓰기 부하를 충분히 처리할 수 있는 IOPS/속도의 스토리지 선택 필요.
- 플랫폼/DBMS 호환성
- 윈도우, 리눅스, 오라클, MS-SQL 등 사용 환경별로 지원 방식 및 요구사항이 다를 수 있으니, 사전 호환성 검토 필수.
요약 표
| 구분 | 설명 |
| 구조 | 두 개 이상의 노드가 동시에 연결 가능한 스토리지 (한번에 한 노드만 소유) |
| 목적 | 장애 발생 시 데이터 보호 및 서비스 무정지 운영 |
| 주의점 | 스토리지 이중화, 소유권 전환, 파일 시스템 잠금, 성능 설계 |
| 적용 예시 | MS-SQL FCI, Oracle RAC의 일부, 클라우드 Shared Disk 기반 클러스터링 |
3.Mysql replication
mysql replication 방식에 대한 개념 및 read node 1개에서 3개로 확장시 고려사항은?
1. MySQL Replication 방식
MySQL에서 일반적으로 사용되는 Replication(복제) 방식은 다음과 같습니다:
| 구분 | 설명 |
| Asynchronous Replication(비동기 복제) | 마스터 서버에서 변경된 데이터를 슬레이브로 전송하지만, 마스터가 먼저 처리 완료 후 슬레이브로 전송됨. 슬레이브와 데이터가 일시적으로 불일치할 수 있음. |
| Semi-synchronous Replication(반동기 복제) | 마스터가 트랜잭션을 커밋하는 시점에 최소 1개 슬레이브로부터 "수신" 확인을 받아야 커밋 확정. 데이터 일관성이 향상되지만 약간의 레이턴시 증가. |
| Synchronous Replication(동기 복제) | [MySQL NDB Cluster] 등 일부 엔터프라이즈 환경에서 지원. 모든 슬레이브가 변경 내용을 받아야만 마스터 트랜잭션 커밋이 완료됨. 고강도의 데이터 일관성 보장. |
실제 운영환경에서는 Asynchronous 방식을 가장 많이 사용하며, 데이터의 무결성과 중요성에 따라 Semi-synchronous 방식을 선택하기도 합니다.
2. Read Node(복제 슬레이브) 확장 방법
기본 구조
- MySQL Replication은 Master(Write)와 Slave(Read) 구조로 구성됩니다.
- Master 서버에서 발생하는 데이터 변경(INSERT, UPDATE, DELETE 등)은 Binary Log에 저장되고,
- Slave 서버가 이를 읽어서 데이터베이스 상태를 지속적으로 동기화합니다.
Read Node 확장 예시 (1개 → 3개)
기존(슬레이브 1개)
(Write/Read)
Master
|
--------------
| |
Slave1 (read) (Optional: Application Connect)
확장(슬레이브 3개)
plaintext
(Write/Read)
Master
|
-------------------
| | |
Slave1 Slave2 Slave3
(Read) (Read) (Read)
- 각 Slave는 Master로부터 별도로 데이터를 복제 받아 최신 상태를 유지합니다.
- 애플리케이션(or 로드밸런서)이 Read용 질의를 Slave1~3에 분산하여 읽기 성능을 크게 높일 수 있습니다.
확장 단계별 설명
- 신규 Slave 노드(MySQL Instance) 2대 추가 구축
- 새 서버에 MySQL 설치 및 초기 데이터베이스 동기화(예: mysqldump 또는 xtrabackup 사용).
- Master에서 추가 노드용 Replication 계정 및 권한 발급
- Slave2/Slave3에 복제 설정
- CHANGE MASTER TO ... 명령을 사용하여 Master 연결 정보와 Binlog Position 지정
- START SLAVE; 실행
- Replication 정상여부 확인
- SHOW SLAVE STATUS\G 명령으로 동기화 상태 점검
- Application/로드밸런서에서 Read 질의 분산
- 읽기 질의를 3개 노드에 라운드로빈 또는 가중치 분산하여 처리량 향상
도식화
▲
| (Write/Read)
Application
/ | \
Slave1 Slave2 Slave3
(Read) (Read) (Read)
↖ | ↗
Master
(Write)
장점
- 읽기 연산 성능 수평적으로 확장 가능.
- 장애시 읽기 노드 단순 교체 가능.
- 쓰기 연산은 Master에 집중.
유의사항
- 비동기 복제의 경우, 최신 데이터가 슬레이브에 약간 늦게 반영될 수 있음(Replication Lag).
- 쓰기 노드는 여전히 하나이므로, Write 성능 확장은 별도 구성 필요(예: Sharding).
- Binlog 사이즈와 네트워크 대역폭 고려 필요.
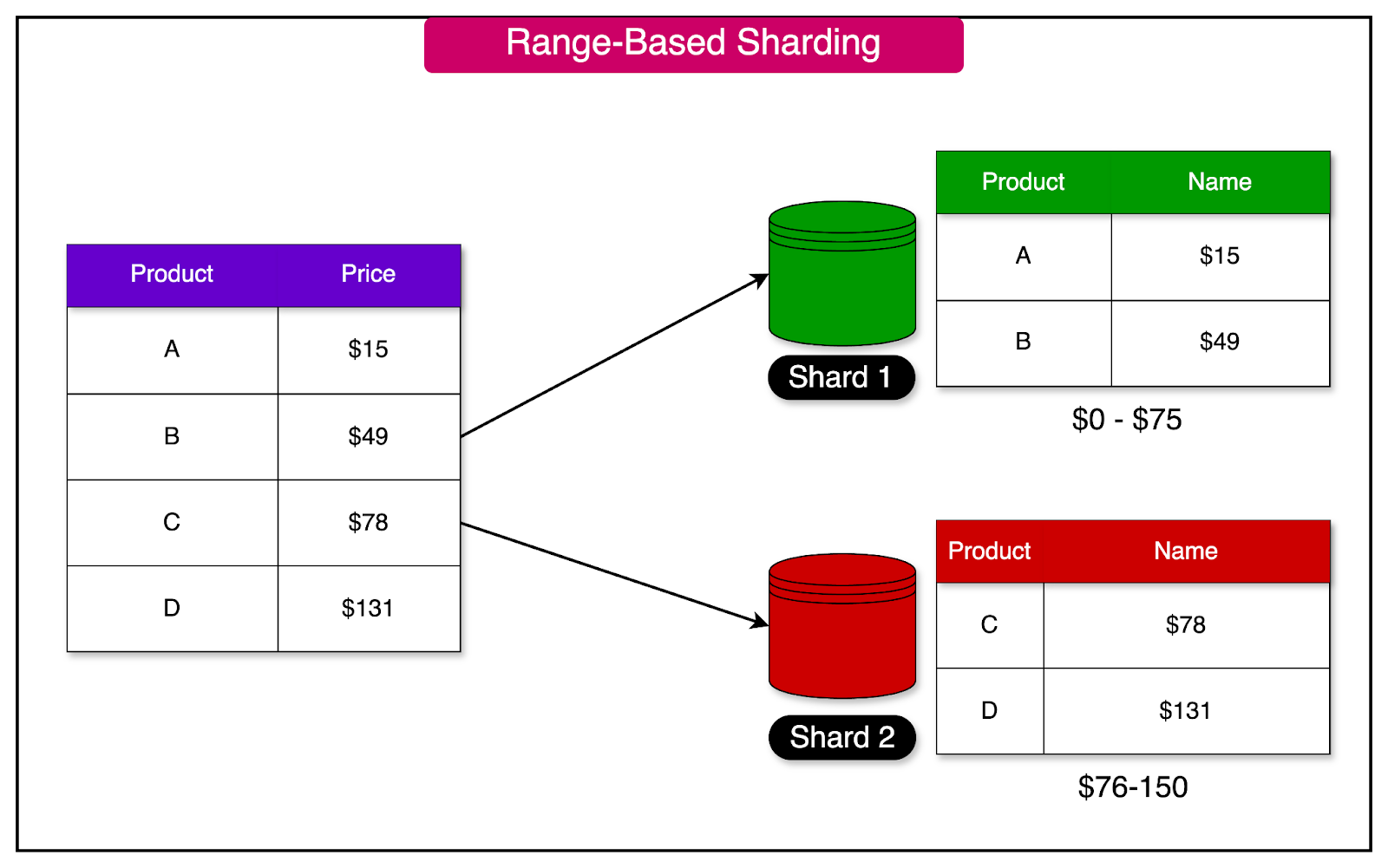
**sharding
4.redis 기반의 session clustering 및 복제를 통한 고가용성에 대해
1. 세션 클러스터링 개요
- Redis 세션 클러스터링은 다양한 애플리케이션 서버(예: 웹 서버)가 사용자 세션 데이터를 공유하도록 해, 어느 서버로든 트래픽이 분산되어도 세션 정보 일관성을 보장할 수 있게 만듭니다.
- 여러 서버가 Redis를 공통 세션 저장소로 이용함으로써, 서버 장애나 확장에도 사용자는 일관된 세션 경험을 얻을 수 있습니다.
2. 고가용성(HA)을 위한 복제
- Redis 복제(replication) 기법을 활용하면, 하나의 Redis 인스턴스(마스터)가 쓰기 작업을 처리하고, 다른 인스턴스들(슬레이브)이 실시간으로 데이터를 복제합니다.
- 장애가 발생해 마스터가 사용 불가해질 경우, 슬레이브가 새로운 마스터로 승격될 수 있어 세션 데이터가 손실되지 않습니다.
- Redis Sentinel 또는 Redis Cluster를 통해 장애 감지와 자동 failover가 가능합니다.
3. 대표적인 고가용성 구조
| 구성 요소 | 역할 |
| Redis Master | 세션 데이터 주요 쓰기/읽기 처리 |
| Redis Slave(s) | 마스터 데이터 실시간 복제, 장애 시 마스터 역할 승계 |
| Redis Sentinel/Cluster | 장애 감지 및 자동 failover 관리 |
| 애플리케이션 서버 | Redis를 통한 세션 데이터 기록/조회 |
4. 장애 대응과 무정지 서비스
- 세션 데이터가 Redis에 저장되므로, 애플리케이션 서버 중 하나가 장애를 겪어도 다른 서버에서 세션 정보 접근이 가능합니다.
- Redis 마스터 장애 발생 시 Sentinel이나 Cluster가 이를 감지하고 슬레이브를 마스터로 전환, 자동 복구가 이루어집니다.
- Traffic 분산과 세션 일관성 유지가 가능하여 무정지 서비스를 제공할 수 있습니다.
5. 실무 적용 시 유의사항
- 세션 타임아웃 설정 등 Redis의 key 만료 정책을 활용해 세션 메모리 관리가 필요합니다.
- 네트워크 파티션이나 일시적 장애에 대비한 적절한 설정과 모니터링이 중요합니다.
- 보안 강화를 위해 Redis 액세스 제어, TLS 암호화 등도 적용할 수 있습니다.
5.Azure Temporary Disk는 무엇이고 운영상 유의할 점은 무엇인가?
Azure의 Temporary Disk는 Azure 가상머신(VM)에 기본적으로 제공되는 임시 저장소로, 일반적으로 D: 드라이브에 연결되어 있습니다. AZURE TEMPORARY DISK의 개념과 함께 운영 시 반드시 알아두어야 할 유의점을 아래와 같이 정리합니다.
1. Temporary Disk 개요
- 역할
- 운영 체제(OS) 디스크 및 데이터 디스크와 별도로 제공되는 로컬 디스크.
- 빠른 I/O를 제공하며, 주로 페이지 파일, 임시 파일 저장 등의 용도로 활용.
- 구성 위치
- VM과 물리적으로 동일한 호스트 머신의 로컬 저장소에 매핑됨.
- 크기
- VM의 크기(SKU)에 따라 할당 용량이 다름.
2. Temporary Disk의 특징 및 유의점
주요 특징
- 비휘발성 데이터 저장 불가
- VM 재부팅, 할당 해제(deallocate), 하드웨어 장애(호스트 재배치 등) 발생 시 저장된 데이터가 모두 삭제됨.
- 지속적으로 보존해야 하는 데이터 저장에 절대 사용하면 안 됨.
- 용도 제한
- 페이지 파일, 교환 파일(swap file), 기타 OS에서 임시 데이터를 저장하는 용도로 사용 권장.
- 애플리케이션 로그, 데이터베이스 파일 등 주요 데이터 저장에는 사용 금지.
운영상의 유의점
- 백업 불가
- Temporary Disk에 저장된 데이터는 Azure 백업, Snapshot 등과 연계 불가.
- 데이터 손실 주의
- 임시 디스크에 중요한 데이터를 저장하면 VM 동작 중지 또는 재할당 시 모두 손실됨.
- 디스크 식별
- 일반적으로 Windows VM의 경우 D:, Linux VM에서는 /dev/sdb 등에 마운트되어 있음.
- 디스크 사이즈 확인
- VM 크기별 temporary disk 용량이 다르므로 사전에 크기를 확인하고 설계해야 함.
- SSD 속도
- SSD 기반 스토리지이므로 빠른 read/write 작업 가능 (단, 영속성은 보장 불가).
- 운영 가이드
- 임시적으로만 필요한 파일, 캐시, 변환용 데이터 처리 등에만 사용해야 안전함.
요약 표
| 구분 | Temporary Disk (예: D:) |
| 영속성 | 비영속, 일시적 저장(데이터 손실 가능) |
| 주요 활용 용도 | 페이징 파일, 임시 데이터 |
| 금지 용도 | 중요/영구 데이터, 백업 필요 데이터 |
| 크기 | VM 사이즈에 따라 상이 |
| 속도 | 빠른 로컬 스토리지 |
실무 팁
- 주요 데이터는 항상 Managed Disk(OS, Data Disk) 또는 Azure Files, Blob 등 영구 스토리지 서비스에 저장해야 합니다.
- 임시 디스크에 데이터베이스, 중요한 로그 등을 저장하면 복구가 불가능하므로 반드시 주의해야 합니다.
6.기존시스템을 Azure로 이관시 Application Gateway와 가용성 구성
1. Application Gateway 구성
- Application Gateway는 Azure의 L7(HTTP/HTTPS) 부하 분산 서비스로, 웹 트래픽에 특화되어 있습니다.
- 여러 가용성 영역(Availability Zone)에 분산 배포(Zonal 또는 Zone-Redundant 옵션 지원)하면, 단일 영역 장애 시에도 서비스를 계속 제공할 수 있습니다.
- 백엔드 풀에는 여러 VM 또는 VMSS(가상머신 확장 집합)로 구성된 웹/앱 서버들을 등록합니다.
2. 고가용성(HA) 설계 방안
| 핵심 요소 | 권장 구성 |
| Application Gateway | Zone-Redundant 모드 활성화, 여러 가용성 영역에 분산 배치 |
| 백엔드 서버(Web/App) | VMSS 활용 또는 VM을 Availability Set/Zone에 분산 배포 |
| 데이터베이스 | Azure PaaS DB(Azure SQL/Managed Instance) 또는 이중화 구성 활용 |
| 네트워크 구성 | 프론트와 백엔드에 별도 서브넷 할당, NSG/방화벽 적용 |
| 이중화 및 DR | 필요시 Traffic Manager 등 사용해 다중 리전 이중화 |
7.Azure 아키첵처
Azure 아키텍처 센터 URL : https://learn.microsoft.com/ko-kr/azure/architecture/
<![if !supportLists]>Ø <![endif]>HA/DR용으로 빌드된 Multi-Tier Web Application

다중 지역 부하 분산 아키텍처

8.서술형
Q1
1. WEB/WAS 서버 Scale-Out에 따른 아키텍처 변경
A. 부하분산(Load Balancer)
- Load Balancer 재설정
- WEB과 WAS 서버 모두 각 계층 앞단에 L4/L7 Load Balancer(예: Azure Load Balancer, Application Gateway, F5 등)에서 백엔드 풀을 기존 2대 → 4대로 확장 등록.
- 라운드로빈, 세션 퍼시스턴스 등 정책 재점검.
B. 네트워크/가용성 구성
- 서버 증설에 따른 네트워크/서브넷 및 IP 재할당
- 확장된 서버들이 현재 서브넷/네트워크 내에 무리 없이 수용 가능한지(서브넷 용량, Security Group 등).
- 서버 장애 대비
- WEB, WAS 서버를 서로 다른 가용성 영역(Availability Zone/Set)에 분산하여 고가용성 확보.
C. 세션 관리
- 세션 클러스터링 또는 중앙집중 세션 스토리지 필요성
- WEB/WAS 서버가 늘어날수록 Sticky Session(세션 오염/편중) 문제가 발생할 수 있음.
- Redis 등 외부 중앙 세션 저장소 또는 애플리케이션의 분산 세션 관리 도입 권장.
D. 환경 자동화 및 스케일링
- Auto Scaling 설정
- 요청 수, CPU, 네트워크 트래픽 등 트리거 기반 자동 증감 설정.
- 구성 관리/배포 자동화 도구(CI/CD) 활용
- 서버 증설 시 애플리케이션 배포 자동화 필요.
2. DB(Oracle RAC) 데이터 증가에 따른 대책
A. Storage(저장소) 확장
- DB 볼륨 용량 증가
- 신규 LUN 추가, 스토리지 확장 또는 성능 극대화를 위한 IOPS 보강.
- 스토리지 성능(throughput, IOPS) 모니터링 강화
B. DB 스케일업/스케일아웃 검토
- Oracle RAC Node 수 추가 고려
- RAC의 Scale-Out 한계, 라이선스 비용 및 성능 기대치를 검토.
- Sharding 등의 분산 DB 전략 검토(데이터 증가가 아주 크다면)
C. 백업 및 DR 구조 재점검
- 증가하는 데이터 대비 백업, 아카이빙, 재해복구(BC/DR) 전략 재수립 필요
- 백업 주기, 증분 백업 정책 등 점검
3. 모니터링과 보안
- 모니터링 시스템 확장
- 서버 수 증가에 따른 리소스, 애플리케이션, 트랜잭션, DB 성능 모니터링 범위 확장.
- 방화벽 및 보안정책
- 신규 서버/포트에 대한 접근제어(방화벽, NSG, ACL 등) 업데이트.
4. 예시 아키텍처 요약
| 계층 | 변경 전 | 변경 후(확장) |
| Web | 2대(LB 앞단) | 4대(LB 앞단, 세션 클러스터링 필요) |
| WAS | 2대(Web 뒤 LB) | 4대(Web 뒤 LB, 세션 클러스터링/중앙화 필요) |
| DB | 2대(Oracle RAC) | 스토리지 확장, Node 추가가능 여부, DR/Backup 강화 |
5. 추가 고려 사항
- 확장 시 서버/DB 라이선스 및 운영 예산 증액 필요
- 배포 관리, 트래픽 분산, 장애 조치 영역 전체적인 프로세스 정비
- 애플리케이션 코드에서 확장성, 세션처리 로직 점검
Q2
| Scale-out이후 DB서버의 물리 메모리가 모두 소진되어 Swap-out이 자주 발생하여 서비스 Response Time이 급격히 늦어지나 응답이 없는 경우가 발생하고 있다. 관련 해소 방안은 무엇인가? |
1. 메모리 증설(Scale-up)
- 가장 확실한 근본 해결책은 DB 서버의 물리적 메모리(RAM)를 증설하는 것입니다.
- 데이터 증가, 세션/연결 수 증가로 인한 SGA/PGA 사용량 확대에 대응.
- 반드시 서버 재기동 및 용량 계획 수립과 병행.
2. DB 메모리 파라미터 조정
- SGA, PGA 등 Oracle 메모리 파라미터를 현 서버 메모리 용량과 DB 부하 특성에 맞게 조정
- SGA_TARGET, SGA_MAX_SIZE, PGA_AGGREGATE_TARGET 등 값 점검 및 최적화.
- 불필요하게 과다하게 할당하여 실제 메모리 초과 및 Swap 유발되는지 확인.
3. 불필요한 서비스/프로세스 정리
- DB 서버 내 필요 없는 서비스, 백그라운드 실행 또는 추가 프로그램 종료
- OS 차원에서 불필요한 프로세스, 데몬 확인 및 정리(특히 DB 전용 서버일 경우).
4. 쿼리/워크로드 튜닝
- 메모리 점유가 높은 쿼리 확인, 어플리케이션/DB 쿼리 튜닝
- Full Scan, 대량 조인, 불필요한 정렬 등으로 메모리 과다 소모하는 쿼리 탐지 및 개선.
- 자동화/반복 배치작업, 통계정보 갱신 주기 등 재점검.
5. 세션/커넥션 관리 정책 강화
- Connection Pool 크기, 세션 타임아웃, 불필요하게 열린 세션 강제 종료 설정
- 연결 수가 필요 이상으로 많아지는지 점검(특히 WAS Scale-out 이후).
6. Swap 사용량 모니터링 및 알림
- OS 및 DB 모니터링 툴에 swap 사용량 및 메모리 임계치 알림 설정
- Swap 발생 전 조치 가능하도록 자동 경보 체계 구축
7. 스케일-아웃/분산 전략 추가 고려
- 부하가 계속 증가한다면 Oracle RAC 노드 추가, 혹은 테이블/서비스분할(Sharding) 등 분산 전략을 병행 검토
8. 재기동 등 임시 조치
- 단기 응급조치로는 서비스 부하 시간 외에 DB 프로세스 또는 OS 재기동을 할 수 있으나, 근본적이지는 않습니다.
Q3
| IT부서에서 최종적으로 RAC를 2node에서 3node로 확장하기로 방향성을 잡았다. 최근 Azure로의 환경전환 최우선 정책에 따라, On-premise와 Azure 2개 환경에서의 RAC 1개 노드 추가 절차를 설명하라 |
On-premise 환경에서 RAC 3번째 노드 추가 절차
- 신규 노드 준비
- 하드웨어, OS(Oracle 호환 버전), 패치 적용
- 기존 RAC 노드들과 동일한 네트워크(인터커넥트, 퍼블릭, VIP 포함), 저장소(공유 디스크), 사용자/그룹 환경 세팅
- 필수 패키지 및 환경설정
- OS 커널 파라미터, 의존 패키지 설치
- Oracle Grid Infrastructure 패키지와 동일하게 준비
- 공유 스토리지 연결
- 기존 RAC의 공유 디스크(ASM, Cluster File System 등)에 신규 노드 연결 및 인식 확인
- Oracle Grid Infrastructure 소프트웨어 설치
- 기존 클러스터 홈에서 addNode.sh 스크립트 실행
- 예:
sh
$GRID_HOME/addNode.sh -silent "CLUSTER_NEW_NODES={newnode}"
- OUI(Oracle Universal Installer) 또는 클러스터 관리자(CRSCTL)로 추가
- Oracle RAC 소프트웨어 설치
- RDBMS 소프트웨어도 동일한 방식으로 addNode.sh 실행 or GUI에서 노드 추가
- 노드 클러스터 등록 및 서비스 구성
- 추가된 노드가 CRS에 등록되었는지 확인(crsctl, srvctl 등)
- 각종 서비스, 리스너, 인스턴스가 새 노드 포함되도록 재구성
- 검증
- CRS/Oracle 인스턴스 정상 구동 확인
- 클러스터 노드 상태 조회 (olsnodes, crsctl status resource, srvctl status instance 등)
- 인터커넥트, 스토리지 IO 정상 동작 확인
Azure 환경(Oracle RAC on Azure IaaS)의 노드 추가 절차
- Azure VM 준비
- 동일한 VM 사이즈, OS 이미지, 네트워크(서브넷, NVA 등)로 신규 VM 생성
- 가용성 집합(Availability Set) 또는 가용성 영역(Zone)에 기존 RAC와 연동
- Azure 내부, 외부 부하분산(VIP필요시 Azure Load Balancer 구성 등) 환경 고려
- 공유 디스크 연결
- 신규 VM(노드)에 Azure Managed Disk(프리미엄 SSD 등) - 기존 RAC 공유 디스크에 모두 연결
- 공유 디스크 지원 옵션(region, OS) 확인
- OS, 패키지, 커널 설정
- 기존 RAC 환경과 동일하게 맞춤
- Azure에서 권장하는 보안 및 네트웍 설정 추가 적용
- Oracle Grid Infrastructure 및 RDBMS 설치
- On-premise와 동일, 기존 홈에서 addNode.sh 실행
- 필요한 포트(인터노드, DB 접근, 클러스터 관련) NSG에서 오픈
- VIP, Interconnect IP 등 Azure 규격 신경써서 구성
- Azure 내부 네트워크(VNet) 및 부하분산 옵션을 활용하여, Public/VIP/인터커넥트 IP를 적절히 할당
- Azure Load Balancer(ILB)와 VIP 구성을 연동
- 클러스터 등록 및 서비스 추가
- Oracle CRS에 추가 노드 등록, 인스턴스 추가 등
- 필요한 경우 Azure의 Scale Set, 스토리지 자동배포 스크립트 등 활용
- 검증 및 문서화
- 클러스터 상태, 노드 정상 동작 확인
- Azure Portal, 오라클 CRS 상태 모두 점검
- 운영 자동화 방식 준비 및 백업정책 재확인
공통 참고 사항
- 노드 추가 전 백업, 메인테넌스 윈도우 확보, 클러스터 상태 정상인 상태에서 진행
- OS, Oracle, 클러스터의 패치 레벨이 모든 노드에서 일치해야 함
- 스토리지, 네트워크, 보안/방화벽(Group/NSG) 정책 선점검
요약표
| 단계 | On-premise | Azure |
| 1. 노드 준비 | 물리/가상 서버, OS, 네트워크 구성 | Azure VM, VNet, Availability Set |
| 2. 공유스토리지 연결 | SAN/NAS, ASM 등 직접연결 | Azure Managed Disk, 공유스토리지 구성 |
| 3. OS/패키지 설치 | 커널/의존 패키지/환경설정 | 동일 + Azure 지원 환경설정 보완 |
| 4. 소프트웨어 설치 | addNode.sh, Grid/RDBMS Home 관리 | 동일 |
| 5. 네트워크/VIP | 직접 연동, VIP, 인터커넥트 | Azure ILB/VIP, NSG 추가 설정 |
| 6. 클러스터 등록/검증 | CRS 등록/서비스 확인 | Azure Portal/CRS 동시 점검 |